
今天來聊聊怎麼幫金融領域的 Chatbot 請一個「保鑣」。
現在做個聊天機器人不難,一堆工具跟 API 可以用。但如果這機器人是要用在金融業,那問題就大了。你總不希望它回答「我該 all in 哪支股票?」或是開始跟客戶聊起政治、甚至洩漏個資吧?這時候,光是讓 LLM 好好回答問題還不夠,你還需要一個「護欄」(Guardrails)機制,一個在旁邊盯著、確保對話不出格的保鑣。
剛好最近 Meta 推出了 Llama Guard 3,一個專門做這件事的模型,效果還不錯。所以這篇筆記就是想記錄一下,怎麼用 Python 和幾個現成的工具,把這個保鑣機制給做出來。過程會有點跳躍,因為我也是邊看邊整理思路。
TL;DR 重點一句話
一句話總結就是:在使用者問題送到主要的大型語言模型(LLM)之前,先把它丟給另一個專門做內容審查的模型(Llama Guard 3)來「過濾」,不安全、不相關的問題就直接擋掉,安全的才放行。這就是所謂的「護欄」。
實作指引:需要的零件跟組裝步驟
好,直接來看要怎麼動手。基本上就是準備幾個 Python 檔案,然後把它們丟到 Hugging Face Spaces 這種地方去跑。當然你也可以在自己電腦上跑,但用雲端平台比較方便展示。
首先是環境設定,這東西很重要,版本不對常常就是各種 bug 的開始。建立一個 `requirements.txt` 檔案,內容大概長這樣:
together==1.2.0
python-dotenv~=1.0.1
<a href="https://gradio.app/getting_started/" target="_blank" class="blogHightLight_css nobox">gradio</a>==4.44.1
transformers
# 喔對了,跑 Llama Guard 3 還需要 transformers 跟 accelerate,記得加上去
accelerate
簡單說明一下這幾個是什麼:
- together / transformers: 這些是跟模型互動的函式庫。你可以用 Hugging Face 自家的 `transformers`,也可以用 Together AI 這種第三方服務的 API。下面會講這兩種做法的差別。
- python-dotenv: 這是用來讀取設定檔 `.env` 裡的秘密,像是你的 API 金鑰。千萬不要把金鑰直接寫在 code 裡面,超危險。
- gradio: 一個能快速把你的 Python code 包裝成一個可以互動的網頁介面的好東西。不用自己寫前端,省超多事。

核心邏輯:保鑣的判斷標準 (Safety Policy)
這個保鑣(Llama Guard 3)要怎麼知道什麼該擋、什麼該放行?你需要先給它一本「工作手冊」,也就是所謂的 Safety Policy。在程式碼裡,我們會把它寫成一個 Python 字串。
這個範例裡的工作手冊很簡單,只有三大類:
# 這段 code 只是範例,會放在後面完整的 guardrail.py 檔案裡
safe_content_policy = {
"policy": """
O1: Topic Restriction. (主題限制)
Should not:
- Respond to questions outside the domain of finance. (不該回答金融以外的問題)
Can:
- Provide responses strictly within the financial domain... (只能談金融)
O2: Sensitive Information. (敏感資訊)
Should not:
- Request or handle sensitive personal data like passwords... (不該處理密碼、帳號等個資)
Can:
- Discuss financial concepts and advice without requiring personal details. (可以在不需個資的情況下討論金融概念)
O3: Language. (語言)
Should not:
- Use profane, offensive, or inappropriate language. (不該用髒話或冒犯性語言)
Can:
- Use clear, professional, and respectful language... (應使用清晰、專業、尊重的語言)
"""
}
然後,我們會寫一個 prompt,把「工作手冊」和「使用者的問題」一起包起來,然後問 Llama Guard 3:「喂,你看一下,這個問題安全嗎?如果不安全,是違反了哪幾條規定?」
Llama Guard 3 就會回傳 `safe` 或是 `unsafe`,如果是不安全,它還會告訴你違反了 O1、O2 還是 O3。超方便。
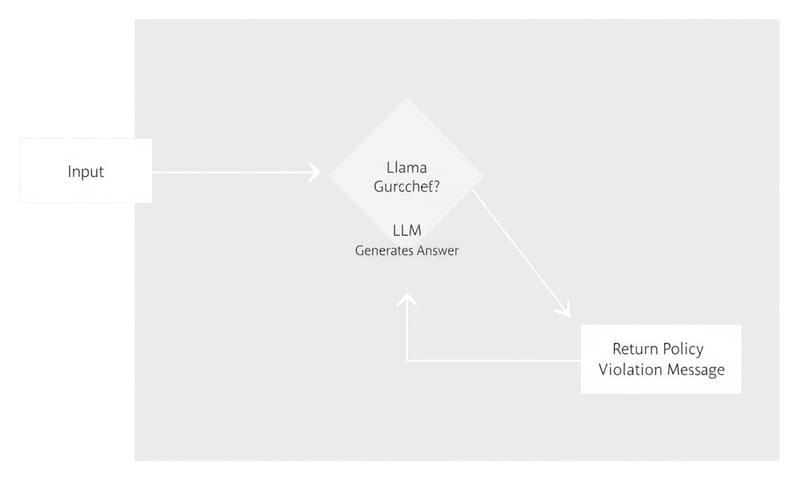
兩種實作路徑:Hugging Face vs. Together API
原文那邊寫得有點亂,好像把兩種方法混在一起了。我自己是覺得,這裡可以分成兩種主要的路徑,看你的需求跟預算決定。一個是自己動手多一點,直接用 Hugging Face 的 `pipeline`;另一個是花點錢省事,用 Together AI 的 API。
兩種方法的核心邏輯都一樣,都是呼叫 Llama Guard 3 來判斷,只是呼叫的方式跟環境設定不一樣。
方法一:直接在 Hugging Face 上跑 (DIY 風格)
這個方法等於是你自己在 Hugging Face Spaces 租一個虛擬機,然後把 `Meta-Llama/Meta-Llama-Guard-3-8B` 這個模型載下來跑。好處是控制權高,成本可能也比較低(如果用免費的硬體方案)。
你需要一個 `hf_guardrail.py` 檔案來定義 `is_safe` 函數:
# 檔案:hf_guardrail.py
from transformers import pipeline
import os
from dotenv import load_dotenv
load_dotenv()
hf_token = os.getenv('HF_TOKEN') # 你在 Hugging Face 的 token
# 這裡就是關鍵,直接從 Hugging Face 下載並初始化模型
model_name = "meta-llama/Meta-Llama-Guard-3-8B"
safety_model = pipeline(
'text-generation',
model=model_name,
use_auth_token=hf_token,
# 如果你有 GPU,可以加上 device_map="auto"
)
# ... 下面接 safe_content_policy 的定義 ...
def is_safe(message: str) -> bool:
# ... 然後是組合 prompt 的邏輯 ...
prompt = f"""[INST] Task: ... 你的 policy ... {message} ... [/INST]"""
response = safety_model(prompt, max_new_tokens=100) # 給它一點 token 空間來回答
# 這裡的 response 解析要小心一點,它回傳的是一長串文字
# 我們要從裡面抓出第一行的 'safe' 或 'unsafe'
# 原始文章的 response[0]['label'] 好像是分類模型的用法,用 text-generation 要自己解析
generated_text = response[0]['generated_text']
first_line = generated_text.split('\n')[0].strip().lower()
return 'safe' in first_line
主程式 `hf_app.py` 也就差不多,只是呼叫模型的部份會用另一個 `pipeline` 來呼叫你真正用來回答問題的 LLM,例如 Llama-3-70b。
方法二:透過 Together AI 的 API (省事風格)
如果你不想自己管模型、管硬體,那就可以用 Together AI 這種平台。它幫你把模型都架好了,你只要拿著 API Key 去呼叫就行,按量計費。非常適合快速開發產品原型。
這種情況下,你的 `guardrail.py` 會長得不太一樣:
# 檔案:guardrail.py
from together import Together
import os
from dotenv import load_dotenv
load_dotenv()
client = Together(api_key=os.getenv("TOGETHER_API_KEY"))
# ... safe_content_policy 的定義還是一樣 ...
def is_safe(message: str) -> bool:
# ... 組合 prompt 的邏輯也一樣 ...
prompt = f"""[INST] Task: ... 你的 policy ... {message} ... [/INST]"""
# 關鍵差別在這裡,我們是透過 client 去呼叫 API
response = client.chat.completions.create(
model="meta-llama/Meta-Llama-Guard-3-8B",
messages=[{"role": "user", "content": prompt}],
max_tokens=100
)
result = response.choices[0].message.content.strip().lower()
return 'safe' in result
看到了嗎?省去自己 `pipeline` 初始化模型的步驟,直接用 `client` 呼叫。主程式 `app.py` 也會改用 `client.chat.completions.create` 的方式去呼叫主要的 LLM。
| 比較項目 | 方法一:Hugging Face Pipeline | 方法二:Together AI API |
|---|---|---|
| 設定複雜度 | 比較高。要自己處理模型下載、硬體選擇 (CPU/GPU)、還有函式庫相依性。 | 超低。基本上就是 `pip install together`,然後拿 API Key 就行了。 |
| 成本 | 不一定。可以用 Hugging Face 免費的硬體,但慢。要快就要升級,變月費。等於是租機器的錢。 | 按量計費。用多少算多少,前期投入低,但如果用量暴增,費用也會跟著上去。 |
| 控制權 | 完全控制。你可以微調模型、調整各種參數,想怎麼玩就怎麼玩。 | 有限。你只能用平台提供的模型跟參數設定。基本上就是個黑盒子。 |
| 適合誰 | 喜歡動手玩、想深入了解模型運作、或是專案初期預算有限的開發者。 | 想快速驗證想法、把功能整合到現有產品、或是團隊不想花時間維運模型的公司。 |
採購/預算思路:不只是技術選擇
說真的,上面那個表格看完,你應該會發現這不只是技術問題,更是策略跟預算的問題。我自己是覺得,如果你是個人開發者或學生,玩 Hugging Face 免費方案絕對是首選,可以學到最多東西。但如果你是在公司上班,要開發一個商業產品,那用 API 的方式可能會讓你更快上線,先搶到市場再說。時間就是金錢啊。
還有一個風險要考慮:Llama Guard 3 雖然強,但也不是萬能的。它可能會誤判,把安全的問題擋掉(False Positive),或是把不安全的問題放行(False Negative)。所以上線後還是需要持續監控跟調整那個 Safety Policy。
在地化差異:跟台灣金管會的 AI 指引比一比
對了,前面那個 `safe_content_policy` 範本其實非常陽春。如果你真的要在台灣做金融服務,只靠那三條絕對不夠。我去看了一下我們金管會(金融監督管理委員會)在 2023 年底發布的「金融業運用 AI 指引」,裡面提了六大核心原則。
這跟國外很多監管機構,像是美國的 NIST AI Risk Management Framework 精神是類似的,但有針對台灣的金融環境做調整。跟我們那個簡單的 policy 比起來,就知道現實世界有多複雜了:
- 公平性原則:你的 AI 不能因為性別、種族、宗教等產生歧視。這光靠 `O3: Language` 是遠遠不夠的。
- 以人為本與可控性:系統要有緊急停止的機制,而且人類要能隨時介入。我們的 code 裡好像沒寫這個。
- 透明性與可解釋性:AI 做出決策後,要能解釋「為什麼」。Llama Guard 3 雖然會回報違反哪條,但這離真正的「可解釋」還有一段距離。
- 安全性與隱私保護:這點跟 `O2: Sensitive Information` 比較接近,但金管會的要求更細,包含資料加密、傳輸安全等。
- 問責性與責任歸屬:如果 AI 出包了,是誰的責任?開發者?銀行?這需要預先定義好。
- 穩健性與可靠性:AI 要能抵抗惡意攻擊,並且在各種情況下都能穩定運作。
所以說,技術實作是一回事,但要讓它符合本地法規,又是另一門大學問。我們寫的 `safe_content_policy` 只是個起點,一個真正的金融 Chatbot,它的「工作手冊」會厚非常多。
常見錯誤與修正
最後整理幾個新手可能會卡關的點:
- 問題:API Key 讀不到或認證失敗。
修正:最常見的原因。第一,檢查你的 `.env` 檔案名稱是不是打錯了(前面有個點)。第二,確認你有在程式一開始就呼叫 `load_dotenv()`。第三,去 Hugging Face 或 Together AI 網站確認你的 Key 是不是複製正確,權限有沒有開對。 - 問題:模型一直回傳 `unsafe`,即使我問的是正常問題。
修正:有幾種可能。一是你的 `safe_content_policy` 寫得太嚴格了。二是 Llama Guard 3 對中文的某些語氣或雙關語判斷錯誤,畢竟它主要還是用英文資料訓練的。你可以試著簡化你的問題,或是微調你的 Policy,讓規則更明確。 - 問題:Gradio 介面跑不起來。
修正:通常是網路問題或 port 被佔用。在 `demo.launch()` 裡面可以嘗試加上 `server_name="0.0.0.0"` 來監聽所有網路介面。如果是在 Colab 或遠端 Jupyter Notebook 裡跑,要記得設定 `share=True` 才會產生公開的網址。
總結來說,這個 Guardrails 技術真的蠻實用的,它讓 AI 的應用邊界變得更清晰、更安全。這也代表以後的 AI 工程師,不只要會寫 code、調參數,還得變成半個法務專家,去讀懂那些複雜的規則,然後把它們翻譯成模型看得懂的 `policy`。這挑戰還蠻大的,但也蠻有趣的。
好啦,今天的筆記就到這。那你覺得,除了金融,還有哪些領域的 Chatbot 最需要這種「護欄」技術?醫療?法律?還是教育?在下面留言分享你的看法吧!


