
pg_duckdb 1.0 就是:讓 PostgreSQL 直接把「分析型查詢」丟給 DuckDB 跑,你的 Python 只要連同一個 Postgres 連線就拿得到結果
pg_duckdb 1.0 是 PostgreSQL 擴充套件(extension),讓 PostgreSQL 在同一條 SQL 裡呼叫 DuckDB 的列式分析引擎,包含掃 Parquet/CSV、跑聚合與 join;Python 用 psycopg 或 SQLAlchemy 連 Postgres 就能吃到 DuckDB 算出來的結果,少掉搬資料、匯出檔案那一串。
- 你有 PostgreSQL 當日常交易庫,但分析查詢一跑就拖慢大家
- 你有 DuckDB 想拿來做聚合、join、掃 Parquet,可是一直在搬資料
- 你想維持 一個連線(Python 只連 Postgres),但分析又想快一點
- 你想在 SQL 裡 混搭:Postgres 表 + 外部 Parquet/CSV
我先把話講死一點:這不是魔法,也不是要你把 Postgres 變成資料倉儲。
它比較像是——你本來要把資料搬去 DuckDB 才能好好算,現在改成「讓 Postgres 內部幫你叫 DuckDB 來算」。就這樣。嗯。
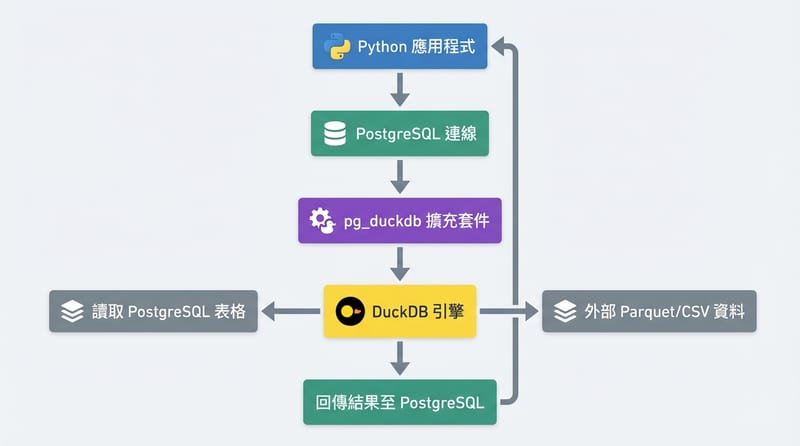
pg_duckdb 在做什麼:Postgres 叫得動 DuckDB,查詢可以「借用」列式引擎
pg_duckdb extension 的核心行為是讓 PostgreSQL 在執行查詢時,能把特定掃描或計算路徑交給 DuckDB 處理,最後結果仍以 SQL 查詢結果回到 PostgreSQL,再回到你的應用端。
你可以得到的幾件事:不是那種「聽起來很猛」的抽象詞,我講具體一點。
- 聚合比較不會卡成一團:像 COUNT、SUM、GROUP BY 那種,DuckDB 的路線本來就是為這種工作設計的。
- 可以掃外部檔案:例如 Parquet、CSV。你不用先把檔案塞回 Postgres 才能查。
- 同一條 SQL 做混搭:Postgres 表跟外部 Parquet 資料一起 join(這點很多人看到會眼睛亮一下)。
- Python 端少一堆雜事:不用匯出 CSV、不用另開 DuckDB 連線、不用做「我只是要算個報表卻搞得像 ETL」那種儀式。
講到「外部 Parquet」,我突然想到台灣很多團隊其實是把檔案丟 S3 相容儲存或內網 NAS,然後每天有人在那邊手動拉檔、重跑 notebook。
你如果看過一次那個流程,會懂我為什麼說:少一個搬運步驟,就少一次「啊幹我忘了更新檔案」的事故。
為什麼 Python 團隊會在意:少掉「搬資料」這段最容易出事的路
對 Python 開發者來說,pg_duckdb 的價值在於你可以維持 psycopg/SQLAlchemy 對 PostgreSQL 的既有連線方式,同時把需要大量掃描、聚合、join 的分析查詢交由 DuckDB 在資料庫內部處理,減少匯出、落地檔、再讀回來的管線成本。
你平常可能長這樣:交易資料在 Postgres,分析在 pandas 或 DuckDB,然後你得把資料「搬出去」。
搬出去這件事,老實說,不是慢而已。
它很容易讓你在某個禮拜五晚上踩到坑:檔案版本不一致、欄位型別被你轉成字串、或者「為什麼這次報表跟上次差 3%」然後開始翻 commit。很煩。真的。
pg_duckdb 的感覺比較像:你 SQL 照寫,你 Python 照連,你只是把「算比較重的那段」交給更適合的引擎。
如果你的痛點是「分析查詢把 Postgres 拖到喘不過氣」,那 pg_duckdb 比較像加一條旁路,而不是整棟房子重蓋。
直接給你看:Python(psycopg2)怎麼呼叫,長得就像一般查詢
在 Python 裡,pg_duckdb 的使用方式通常就是照常連 PostgreSQL,然後在 SQL 裡呼叫 pg_duckdb 提供的函式(例如 duckdb_scan),查詢結果照樣 fetch 回來。
一個很直白的範例:
import psycopg2
conn = psycopg2.connect(
host="localhost",
dbname="mydb",
user="myuser",
password="mypassword"
)
cur = conn.cursor()
cur.execute("SELECT * FROM duckdb_scan('my_table')")
rows = cur.fetchall()
for row in rows:
print(row)
cur.close()
conn.close()你要注意的點:duckdb_scan 是 pg_duckdb 提供的入口之一;實際語法可能會因為你的安裝與設定不同而有差,但概念就是「讓 Postgres 走 DuckDB 的掃描/計算」。
講到這裡我忍不住碎念:不要一看到能掃檔案就開始把所有東西都丟外面,然後再問為什麼權限、網路、延遲把你打爆。
先挑一個報表、一次一個。拜託。
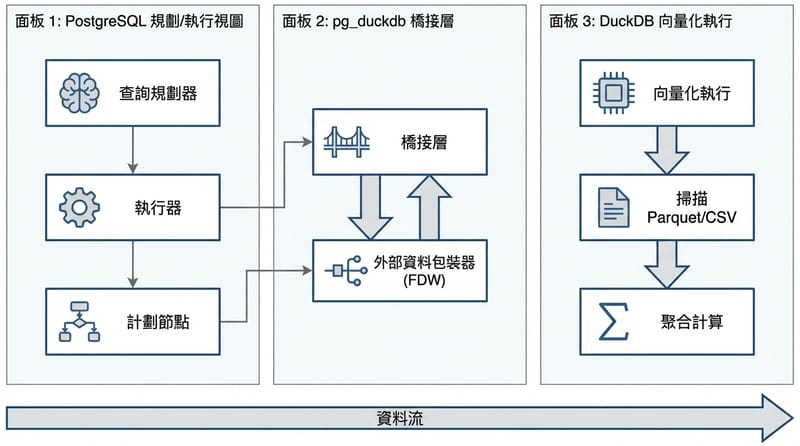
你會用到的「功能清單」:不是每個點都要用,但你要知道它能幹嘛
pg_duckdb 讓 PostgreSQL 能做的事情,大致可以拆成下面幾類;我把它寫得像你在群組裡丟給同事看的那種清單,因為大家真的沒空讀長篇。
| 你想做的事 | pg_duckdb / DuckDB 幫上的忙 | 你要留意的坑(真的會踩) |
|---|---|---|
| 在 Postgres 裡跑比較重的聚合、join | DuckDB 的列式 + 向量化執行路線,通常更適合掃大量資料再算 | 別忘了觀察 Postgres 本身的資源壓力;你只是換引擎算,不是免費午餐 |
| Postgres 表 + 外部 Parquet/CSV 一起查 | 用 duckdb_scan 類似的入口直接掃檔案,再 join 你的表 | 檔案放哪裡、權限怎麼控、I/O 延遲怎麼辦,會比你想的更煩 |
| Python 端維持單一資料庫連線 | 你用 psycopg/SQLAlchemy 照舊,結果一樣是 DataFrame 或 row list | 同事會以為「反正都在 Postgres」然後亂塞查詢,最後你要收拾 |
| 少掉匯出 CSV、手動搬資料那串流程 | SQL 直接查,回來就能用,管線變短 | 短不代表不會壞;部署、版本、extension 管理會變成新日常 |
快問快答:3 個最常見迷思,先拆掉,省得你走冤枉路
迷思一:pg_duckdb 會把 PostgreSQL 變成資料倉儲,所以我不用管 warehouse 了嗎?
pg_duckdb 是把 DuckDB 的分析能力「嵌進」Postgres 的查詢路徑,適合減少搬資料與加速特定分析查詢,但它不等於完整的資料倉儲治理(權限、分層、血緣、成本控管)都自動幫你搞定。
迷思二:裝了 pg_duckdb,我的所有查詢都會自動變快?
pg_duckdb 只對某些分析型工作特別有感(大量掃描、聚合、join),交易型 OLTP 查詢該怎麼寫還是怎麼寫,而且你要監控「哪些查詢被導去 DuckDB」以及導過去後資源怎麼吃。
迷思三:我用的是雲端託管 Postgres,應該也能直接裝吧?
pg_duckdb 需要安裝 PostgreSQL extension;在不少託管服務上,extension 能不能裝、能不能用,取決於供應商支援清單與權限政策,所以你得先確認環境限制,不要到最後才發現「不能裝」。
嗯,這段講完我自己都鬆一口氣。因為真的太多人一開始就用錯期待,然後怪工具。
安裝與部署:本機/自架比較順,託管環境就要先問清楚
pg_duckdb 的安裝方式通常是從原始碼建置,然後在 PostgreSQL 裡 CREATE EXTENSION;這在自架或本機開發環境相對直覺,但在雲端託管 Postgres 上,常見的限制是你沒有權限安裝自訂 extension。
建置(Linux/macOS)長這樣:
git clone https://github.com/duckdb/pg_duckdb.git
cd pg_duckdb
make
make install然後在 Postgres 裡啟用:
CREATE EXTENSION pg_duckdb;小提醒:你如果是團隊環境,extension 版本、Postgres 版本、部署方式(容器?裸機?)最好寫進文件,不然下個人接手會用猜的。
用猜的很痛。
跟 pandas / SQLAlchemy 怎麼搭:你會覺得「咦,就這樣?」
pg_duckdb 對 Python 常見資料工具的重點是「透明」:你照常用 psycopg 或 SQLAlchemy 發 SQL,回來的結果你照常丟進 pandas 或 Polars,差別只是在資料庫端的某些查詢其實是 DuckDB 在算。
pandas 例子:
import pandas as pd
import psycopg2
conn = psycopg2.connect(
host="localhost",
dbname="mydb",
user="myuser",
password="mypassword"
)
df = pd.read_sql("SELECT * FROM duckdb_scan('data.csv')", conn)
print(df.head())突然想到,很多人會問:「那 Polars 呢?」
概念一樣啦,你只要能從 Postgres 拉結果回來,剩下就是你 DataFrame 要怎麼用。就…別把事情想太多。
1.0 代表什麼:可預期的 API、比較敢放進正式環境,但你還是要盯監控
pg_duckdb 1.0 的訊號是開發團隊把它視為穩定且可用於正式環境(production-ready),代表 API 與功能集已成熟到不太會每週改到你爆炸,並且累積了早期使用者回饋來修掉整合與文件問題。
我會怎麼解讀這件事:你可以開始把它放進「不是玩具」的系統設計討論裡了。
但。
你如果想把它丟上線,還是得做你本來就該做的事:監控查詢、看資源、留意相容性。
原文提到的幾個 trade-off,我幫你翻成白話:
- Overhead:多一層 extension 路徑,出事時你要多查一層,不能只怪 Postgres。
- Compatibility:不是所有 Postgres 特性都能跟 DuckDB 的函式愉快牽手,遇到就得拆開。
- Learning curve:團隊要有共識:什麼查詢留在 Postgres,什麼交給 DuckDB;不然最後變成「大家都亂用」。
- Deployment:託管環境不給裝 extension 的話,你就別硬扛,會很狼狽。
我自己的導覽員觀點:pg_duckdb 不是要你變複雜,是要你少掉那些「明明很蠢但每天都在做」的步驟
我看過太多資料流程,真正拖慢人的不是 join 或 group by。
是「人」。
對,就是那個:手動匯出、把檔案丟 Slack、再貼一段 notebook、然後有人忘了跑、有人跑錯環境、有人用舊檔案,最後你得到一個看起來像真的但其實是昨天的數字。
pg_duckdb 這種東西,對我來說是把那條路剪短。
剪短之後,你比較有機會把注意力放回去:資料定義、欄位一致性、誰能查、誰能改。這些才會咬人。
講到「共同格式」,Apache Arrow 這個名字也常被拉出來。
DuckDB 跟 Postgres 都在往能互通的方向走,pg_duckdb 只是其中一塊拼圖。你不用把它神化,但也別忽略它在「少搬一次資料」這件事上的威力。

最後我先預判兩種反對意見:你是哪一派?來吵一下(理性那種)
反對意見 A:「把 DuckDB 塞進 Postgres 不是又多一層複雜度嗎?我寧願管線清楚分開。」
我懂,這派通常很重視邊界清楚、責任切分,覺得一旦混在一起就會難除錯。你講得有道理。
但我也想問:你們現在的「分開」是真的清楚,還是只是把複雜度丟到一堆腳本跟人腦記憶裡?這兩個差很多。
反對意見 B:「我已經有 Snowflake/BigQuery 之類的倉儲了,pg_duckdb 沒必要吧。」
也合理。如果你倉儲那邊治理得很穩,pg_duckdb 可能就只是錦上添花。
但如果你常遇到的是「臨時要查、要 join 外部檔、要在 Postgres 旁邊快速做一段分析」,那 pg_duckdb 可能會讓你少掉一堆手忙腳亂的中繼步驟。
你不用愛上 pg_duckdb,但你至少可以用它測一次:你們團隊到底是被查詢拖慢,還是被搬資料拖慢。
我想聽你一句真心話:你現在最痛的是哪個?
- 查詢跑太久,大家在等結果
- 匯出/搬檔/重跑流程,一直出小錯
- 雲端託管環境不給裝 extension,直接卡死
- 其實都不是,你只是想少寫兩套連線程式碼(我不會笑你)


