
最近...嗯,看到了 Google AI 的一篇新論文,說真的,看完有點不知道該怎麼形容那種感覺。不是那種「喔又有新模型」的感覺,而是...一種「啊,原來 AI 可以這樣搞」的震撼。
他們好像默默地,就打造出一個在做「研究」這件事上,比 OpenAI 最強的研究員模型還猛的系統。而且它的思路,很反直覺,但又...超像我們真正在做事的樣子。
先說結論:這AI強在它很「笨拙」
對,你沒看錯。我自己是覺得,這個新 AI 系統,叫做 TTD-DR,它的核心精神就是模擬我們人類那種...很 messy、很混亂、不斷來回修改的思考過程。
它不是那種一次給你完美答案的天才,反而更像一個很有耐心的學徒,從一份亂七八糟的草稿開始,然後一邊查資料、一邊修改、再根據修改過的東西去問更聰明的問題。嗯,一個循環,一個不斷變清晰的過程。
老實說,這才比較像我們寫論文或做深度報告的樣子吧?哪有人一開始腦中就有完美藍圖的。
現在的 AI 做研究,到底卡在哪?
要理解 Google 這個新東西有多不一樣,可能要先回頭看看現在大部分的 AI Agent 是怎麼運作的。像是 GPT-Researcher 這類開源專案,它們的流程...說好聽是很有結構,說難聽就是很死板。
大概就是三步驟:
- 規劃:啪啪啪,列出一堆它覺得要問的問題。
- 搜尋:然後,一口氣把這些問題全部丟去搜尋,把資料全部抓回來。
- 整合:最後,看著這堆資料,試圖把它們「縫」成一份報告。
這聽起來沒毛病,但問題就出在,這過程是線性的。它在搜尋第二個問題時,根本不知道第一個問題的答案是什麼。等到最後要寫報告的時候,它面對的只是一堆彼此之間沒什麼關聯的筆記。結果...你知道的,產出的東西常常讀起來東拼西湊,感覺沒什麼靈魂。
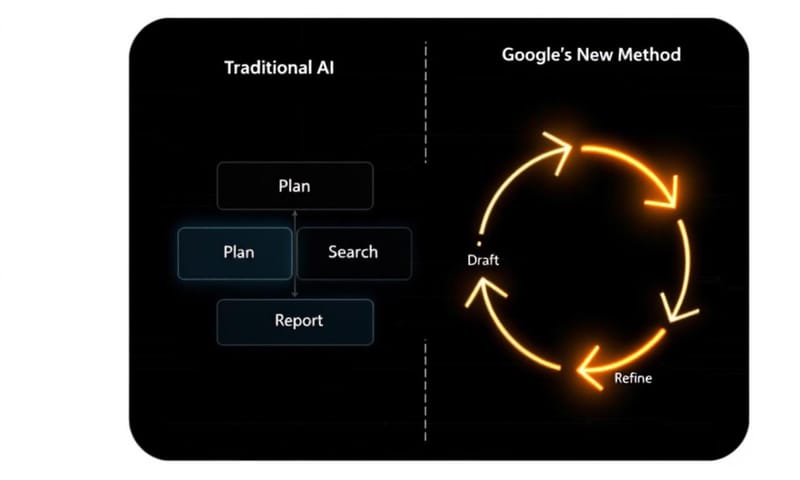
Google 論文裡那張圖,其實就把這個差異畫出來了。你看那些 (a), (b), © 的模型,都是一條路走到黑。但 (d) 這個 Google 的新方法,它是一個「迴圈」。嗯...這個迴圈就是一切的關鍵。
秘密武器:像人一樣「邊寫邊想」
所以,Google 到底怎麼做到的?他們把整個寫報告的過程,看成是一個「擴散過程」(diffusion process)。
這個詞聽起來很學術,但你可以把它想像成...嗯...你有一張非常模糊的照片,幾乎看不出是什麼。然後你用一個演算法,一步一步地把它「去噪」,讓它慢慢變清晰,最後變成一張超高清的照片。TTD-DR 就是用這個概念來「寫報告」。一開始是一份模糊、充滿「雜訊」的草稿,然後慢慢地讓它變得清晰、準確。
這主要靠兩個很聰明的機制。
怎麼做:草稿就是一切,還有個完美主義團隊
這大概是整個系統最核心、也最讓我驚豔的地方。
第一個機制,我會叫它「邊寫邊查,邊查邊改」。
傳統 AI 是先查完才寫,但 TTD-DR 完全相反。它會先用自己腦袋裡(模型內部)的知識,硬幹出一份非常粗糙的初稿。這份草稿可能很多地方不對,也很多空白,但沒關係,它就是整個專案的骨架。
然後,它會看著這份爛草稿,問自己:「嗯...這個地方的說法需要證據」,或者「這個段落還少了什麼?」。接著,它只針對「這一個問題」去搜尋資料。
找到答案後,它不是把資料存起來喔,而是「立刻」回頭去修改剛剛那份草稿。改完之後,一份稍微好一點點的草稿出現了。然後,它再看著這份 2.0 版的草稿,去問出下一個更精準的問題。就這樣一直重複...一直重複...直到整份報告變得超清楚。
你看,它的每一步搜尋,都是被「當下的寫作進度」所引導的。上下文始終都在,這超聰明的。

第二個機制,更誇張,我稱之為「內部組件的自我進化」。
如果說第一個機制已經夠強了,這個簡直是...犯規。在 TTD-DR 這個系統裡,不只是一個 AI 在工作,它更像一個團隊。而且這個團隊裡的每個「人」,都是超級完美主義者。
- 負責規劃大綱的 agent
- 負責想出搜尋問題的 agent
- 負責從搜尋結果總結答案的 agent
- 甚至最後負責潤飾報告的 agent
上面每一個 agent,在輪到它工作的時候,它都會自己跟自己「開會」。例如,輪到要想搜尋問題的 agent 時,它不會只提出一個問題。它會一口氣想出好幾個版本的問題,然後叫另一個 AI 評審來給這些問題打分數,得到回饋後,再修改出一個最好的版本。等於是它每做一件小事,都會自己進行一次頭腦風暴和內部審查。
這就是所謂的「測試時擴展 (test-time scaling)」,意思是在你提出要求「當下」,花費更多的運算資源去做深度的思考和優化,而不是單純依賴一個更大的模型。說真的,這思路完全不一樣。
所以...它真的有用嗎?
有用,而且是那種輾壓式的有用。研究團隊直接把它跟業界最強的幾個對手比較,這裡面甚至包括了像 OpenAI Deep Research 這種不公開的商業系統。
結果很驚人。在寫那種長篇、超詳細報告的測試上(LongForm Research benchmark),TTD-DR 對上 OpenAI 的 agent,勝率是 69.1%。嗯...將近七成的對決都是它贏。在另一個更專業的顧問報告測試(DeepConsult benchmark)上,勝率更高,來到 74.5%,差不多是四分之三的場景都表現得更好。
這不是小小的進步,這幾乎是 KO 對手了。
為了更好理解,我把它們的差異整理成一個簡單的比較表,你看完會更有感覺。
| 比較項目 | 傳統研究型 AI (如 GPT-Researcher) | Google TTD-DR |
|---|---|---|
| 思考流程 | 線性的。規劃 → 大量搜尋 → 整合。像個指令工。 | 循環的。草稿 → 搜尋 → 修改草稿 → 再搜尋... 像個真正的研究者。 |
| 處理上下文 | 很容易丟失。搜尋彼此獨立,最後才兜起來,很破碎。 | 上下文始終存在。草稿就是「單一事實來源」,所有動作都圍繞它。 |
| 產出品質 | 常常像資料的堆砌,讀起來不連貫,缺乏深度。 | 連貫性跟深度都好很多,因為是「長」出來的,不是拼湊的。 |
| 優化方式 | 依賴更大的基礎模型。大力出奇蹟。 | 靠更好的「工作流程」和「即時思考」。每一步都自我優化,很精緻。 |
| 對決 OpenAI 勝率 (顧問報告) | 通常是輸的... 才會需要比較。 | 差不多贏了 3/4 的對局(74.5%),這真的蠻誇張的。 |
論文裡有張圖表也很有趣,它顯示了你給 TTD-DR 越多的「思考時間」,它的表現會不成比例地飆升,那個成長曲線比其他方法都陡峭很多。這代表這個系統不只是聰明,它「變聰明」的效率也高得嚇人。

當然,它還是有極限的
不過呢,說了這麼多,也要說說它還做不到的事。研究人員自己也很坦誠。
目前 TTD-DR 的武器庫裡,只有「網頁搜尋」這一項工具。但真正的研究,還需要很多其他工具,比如直接瀏覽網頁並與之互動(Web Browsing)、跑程式碼做數據分析或模擬(Code Interpreter)等等。
所以,它還不是一個完全自主的 AI 科學家... 還沒啦。但至少,對於所有需要從網路上整合大量資訊來寫報告的任務,它應該是目前最頂尖的了。
這也讓我想到,像是台灣這邊的學術單位,比如之前跟美國史丹佛大學合作發布繁體中文模型的「國科會」,或是我們自己的中研院,他們在做的很多研究其實非常仰賴文獻的梳理跟整合。如果未來這種技術變得普及,對研究人員來說,那種花好幾個禮拜整理文獻的痛苦時光,可能真的會變成幾分鐘的事。這影響...嗯,蠻深遠的。
為什麼我覺得這件事,比想像中更重要
所以,這到底意味著什麼?
從一個角度看,這對所有需要做研究的人——科學家、市場分析師、學生——都是巨大的解放。產出深度報告的時間從「週」縮短到「分鐘」,這幾乎是 AGI (通用人工智慧) 降臨的時刻了。
從另一個角度看,這也代表我們思考如何建構強大 AI 的方式,可能需要轉變了。重點不只是訓練出越來越大的語言模型,更重要的是,要設計出更聰明的「系統」和「工作流程」,去引導這些模型更有效地進行推理。模型周邊的架構,跟模型本身一樣重要。
但對我來說,最大的啟發,可能更哲學一點。
這篇論文證明了一件事:通往超人智慧的鑰匙,可能就藏在一個非常「人性」的過程中——那個充滿混亂、不斷迭代、依靠回饋來修正的寫作循環。
我們那種「先弄個爛東西出來再慢慢改」的傾向,原來不是缺陷,而是通往傑作的必經之路。而現在,我們把這件事,教會了機器。
嗯... 你覺得呢?你有沒有過類似的經驗,覺得自己做事或學習的過程也是這樣「亂七八糟但慢慢變好」?如果 AI 開始用這種方式思考,你最期待它幫你完成什麼事?


