
最近在想一件事,關於工廠裡的數據。我們常常講數位轉型,但好像總是有個瓶頸... 對,就是那個人。
每個工廠或公司,好像都有一個「他」。那個唯一懂數據在哪、怎麼撈的「資料巫師」。你想知道上個月的良率為什麼掉了,要問他。老闆想看某條產線的 OEE 報表,也得排隊等他。他很厲害,沒錯,但他一個人就是個瓶頸。他一請假,整個數據分析就停擺了。說真的,這狀況超沒效率,而且對他本人也不公平。
所以問題到底出在哪?
老實說,這不是那個分析師的錯。問題在於,他的所有知識、那些「A 表格的 a 欄位要跟 B 表格的 c 欄位串起來,但要先排除掉 d 是零的狀況」... 這些寶貴的商業邏輯,全都只存在他的腦袋裡。
當商業世界(比如「我要看上個月的銷售佣金」)跟數據世界(一堆分散的表格、欄位)之間,只有一個「人肉翻譯機」時,這個系統就不可能規模化。
這就是為什麼我們需要「資料模型」(Data Modeling)。簡單講,就是把那位分析師腦中的「翻譯規則」,建成一張大家都能看懂、系統也能理解的地圖。它要把原始、混亂的數據,整理成有意義、方便取用的資訊。
兩種你得先搞懂的資料世界
在我們畫地圖之前,要先知道,資料存放和使用的方式,基本上分成兩種完全不同的世界。這點搞混了,後面會很痛苦。
| 特性 | 交易型資料 (OLTP) | 分析型資料 (OLAP) |
|---|---|---|
| 它的用途? | 就是處理日常營運。像是下訂單、刷卡、ERP 系統的單據... 這些一筆一筆發生的事。 | 為了做分析、看報表、找趨勢。例如,分析「過去一年,哪個產品線的毛利最高?」 |
| 資料長怎樣? | 超級龜毛、正規化。東西都分門別類放在不同的小抽屜,避免重複和錯誤。想找東西要開好幾個抽屜。 | 比較隨性、反正規化。為了讓你方便查詢,會刻意把相關資料放在同一個大桌上,就算有點重複也沒關係。 |
| 處理什麼任務? | 大量的、小規模的、快速的新增、修改、刪除。速度是關鍵。 | 少量的、但一次要看超多資料的複雜查詢。像是加總、平均、比較,問一個問題要翻遍整張大桌子。 |
| 舉個例子? | 電商網站的購物車結帳、銀行的存提款紀錄。 | 分析季度的銷售業績、預測未來的市場需求。 |
所以你看,一個是為了「把事情做對」,一個是為了「從事情中看懂什麼」。工廠現場的 MES 或 ERP 系統通常是 OLTP,而我們要做 BI 報表、戰情室,用的就是 OLAP 的概念。資料模型主要就是在為 OLAP 服務。
OK,那實際上是怎麼做的?
蓋房子有藍圖,資料模型也有。一般會分三個階段,從模糊到精確。
- 概念模型 (Conceptual): 這最簡單,根本就是畫給老闆看的。只有幾個大方塊和幾條線,像是「產品」會被「客戶」下「訂單」。大家對整個系統有個基本共識就好。
- 邏輯模型 (Logical): 這就比較細了。會開始定義每個方塊裡有什麼屬性,比如「產品」有「品名」、「型號」、「成本」。但還不用管是用哪家資料庫、什麼欄位格式,還是用大家看得懂的語言在溝通。
- 實體模型 (Physical): 這就是工程師在看的施工圖了。它會明確定義用的是 SQL Server 還是 PostgreSQL,每個欄位的資料型態是 `VARCHAR(50)` 還是 `INT`,誰是主鍵... 所有技術細節都會在這裡定下來。
我自己是覺得,對大部分非技術背景的人來說,能看懂「邏輯模型」就很夠用了。那張圖,基本上就代表了公司的數據骨架。
你常會聽到的三種主流作法
理論講完了,來聊點業界現在真正在用的東西。當你跟數據團隊開會時,他們嘴裡冒出來的術語,大概離不開這幾個。
1. 星狀結構 (Star Schema) - 久經考驗的老方法
這大概是資料倉儲領域最經典、最基礎的模型了,概念來自 Ralph Kimball 的理論。你可以想像成... 一個核心事實,圍繞著很多描述它的角度。
中間那張叫「事實表 (Fact Table)」,放的都是數字、可以被計算的東西,例如「銷售金額」、「訂單數量」、「生產數量」。
旁邊圍繞著很多張「維度表 (Dimension Tables)」,放的是描述這些事實的背景資訊,也就是你分析時拿來切來切去的「維度」。像是「時間維度」(年、季、月)、「產品維度」(品名、類別、規格)、「客戶維度」(地區、產業)。
它的好處是結構很單純、直觀,查詢效能也好。幾乎所有的 BI 工具(像 Power BI 或 Tableau)都對這種結構做了最佳化。簡單講,先花力氣把數據整理成星星,之後要拉報表就變得很輕鬆。

2. 資料網格 (Data Mesh) - 時髦的分權思想
如果說星狀結構是中央集權,蓋一個超大的中央數據倉儲,那 Data Mesh 就是地方分權。
它的核心想法是,與其讓一個中央的 IT 團隊處理全公司從 HR 到產線的所有數據(他們根本不可能懂所有業務細節),不如把數據的所有權還給最懂這些數據的各個業務單位。
所以,「生產部門」就負責維護和提供「產線數據產品」;「銷售部門」就負責他們的「客戶數據產品」。每個部門就像一個獨立的數據供應商,他們要把自己的數據當成一個「產品」來經營,確保它好用、可靠、容易被別人找到和使用。
這種方法,我自己是覺得... 蠻酷的,但實施起來挑戰很大。它更偏向一種組織文化和架構的變革,而不只是一個技術方案。對很多還在用 Excel 當資料庫的台灣中小企業來說,可能有點太遙遠。不過這個「數據即產品」的觀念,我覺得很棒,不管用什麼架構都該有。
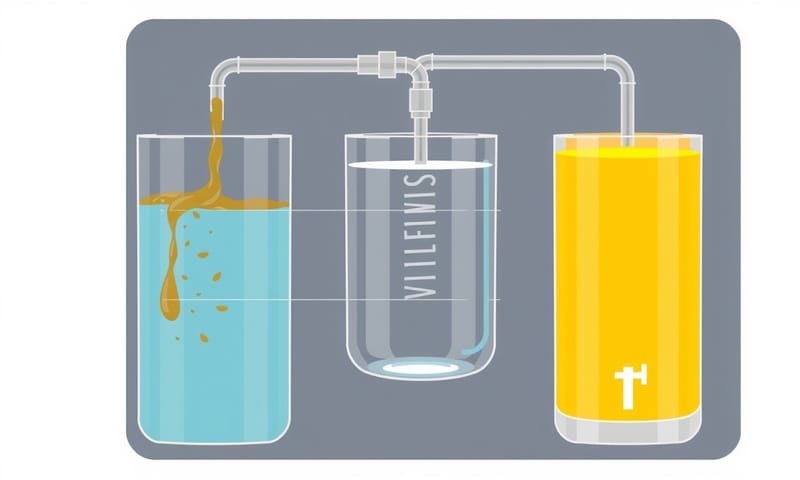
3. 金牌架構 (Medallion Architecture) - 追求純淨的煉金術
這個名字聽起來很炫,但概念其實很好懂。它把數據處理分成三個層次:銅牌、銀牌、金牌。
- 銅牌層 (Bronze): 原始數據區。所有從來源系統(ERP、PLC、感測器)來的資料,不管多髒多亂,原封不動地先丟進來。像是一個數據蓄水池。好處是保留了最原始的紀錄,以後想重新處理都有機會。
- 銀牌層 (Silver): 清洗整理區。這裡的數據會經過初步的清洗、驗證、合併。把一些錯誤值拿掉,把不同來源的資料對應起來。數據已經變得比較乾淨、值得信任了。
- 金牌層 (Gold): 商業應用區。這是最終提供給 BI 工具或分析師使用的數據。它會根據特定的商業需求(例如,做一張毛利分析報表)做高度彙總和聚合。數據在這裡已經變成了可以直接回答商業問題的「黃金」。
這個架構的好處是層次分明,數據品質有保障,而且要追查問題也比較容易。你可以把它想像成一個數據的淨水系統,從泥水(銅)過濾成乾淨的飲用水(銀),最後再按需求調製成果汁(金)。
那...到底該選哪個?
老實說,沒有標準答案。這真的要看公司的規模、數據成熟度、還有預算。
對於大部分剛起步,或是像台灣很多中小型傳產工廠,我的建議是:先從一個簡單的星狀結構開始。把最重要的那個業務流程(例如訂單到出貨,或是生產工單的流程)的數據,用 Power BI 之類的工具,建立一個小的星狀模型。這會讓你馬上看到價值。
不要一開始就想著要搞什麼 Data Mesh 或全公司的 Medallion。那很容易陷入「架構癱瘓」,花了兩年還在開會,一張報表都沒出來。這點跟我們在台灣看到的情況很不一樣,很多歐美大公司分享的案例,他們的資源和組織架構,跟我們本土的環境差距很大。他們可以花大錢請顧問公司導入,但我們可能得從一個懂 Excel VLOOKUP 的廠長開始推動。
先求有,再求好。先把那個「人肉翻譯機」的工作,解放一部分出來,讓系統去承擔。這就是最大的勝利了。
最後來點現實的...
完美的數據烏托邦是不存在的。
不會有那麼一天,你公司的數據倉儲完美無瑕,所有數據都 100% 正確。數據問題永遠都會在,因為商業本身就在一直變。今天多了一個新的產品線,明天改了佣金計算規則,數據模型就得跟著調整。
所以,不要把這些架構當成不可動搖的聖經。把它們當成工具箱裡的工具,目標是建立一個「夠用」、「好維護」,而且大家用起來開心的系統。這比追求一個理論上完美但沒人會用的系統,重要多了。
聊聊你的情況吧!
在你的公司或工廠裡,那個「數據瓶頸」是什麼?是一個特定的人、某個很難用的舊系統,還是根本沒人知道數據在哪?在下面分享一下吧,蠻好奇大家的狀況。🤔


