
嗯...最近,對,最近剛好有機會去碰了一下 Google Cloud 的那個...叫做 Agent Development Kit Hackathon 的活動。老實說,這是我第一次真的去用 ADK 這個東西,就...想說來聊聊這次弄的一個小專案,還有中間學到的一些事。
專案的名字...我自己是叫它「AI Agent 驅動的資料管線事件解決器」。聽起來很長,但其實想法很單純。就是讓 AI Agent 自己去修資料庫 pipeline 的問題。
一句話結論
簡單講,就是用 Google 的 Agent Development Kit (ADK) 串了幾個 AI Agent,讓它們可以自動偵測、診斷、甚至修復資料管線(Data Pipeline)的錯誤,最後還能自己寫一份報告存檔。算是一種...讓管線自己療傷的概念吧。
為什麼要做這個?從一個虛構公司的痛點說起
我想像了一家叫「GlobalSport Emporium」的跨國電商。這種公司,你知道的,每天都有來自世界各地的銷售數據要處理。這些數據要倒進來、轉換匯率、然後產出營收報表...整個流程就是靠一堆複雜的資料管線在跑。
但現實是,這種管線...嗯...很會壞。一下資料格式不對,一下 DAG(有向無環圖)寫錯,或是某個 API 突然掛了。只要一出錯,資料團隊就人仰馬翻,報表出不來,決策也就卡住了。
所以我的想法就是,能不能讓 AI 來處理這些鳥事?讓 Agent 主動去:
- 偵測錯誤:看到報錯,馬上知道出事了。
- 診斷問題:去翻文件、查紀錄,搞清楚是哪裡壞掉。
- 動手修復:如果找到解法,就自己跑 script 或 SQL 把它修好。
- 寫下筆記:修完後,自動生成一份「事件摘要」,記錄下這次是怎麼壞的、怎麼修的,方便以後的人(或 Agent)參考。
我自己是覺得,這比單純叫 AI 寫文案、畫圖...要來得更實用一點,真的能解決一個營運上的痛點。
那...這是怎麼兜起來的?
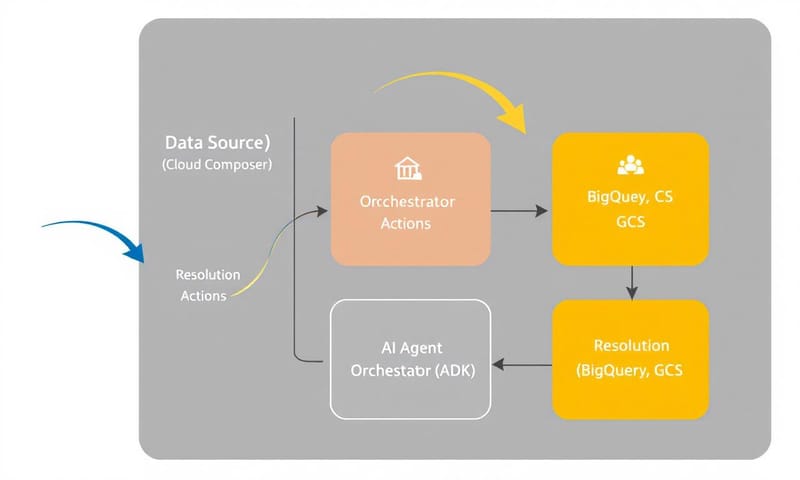
整個系統的核心,就是 Google 的那個開源框架,叫 Agent Development Kit,簡稱 ADK。你可以用 Python 或 Java 去定義一堆不同功能的 AI Agent,然後讓它們分工合作,一起解決一個大問題。
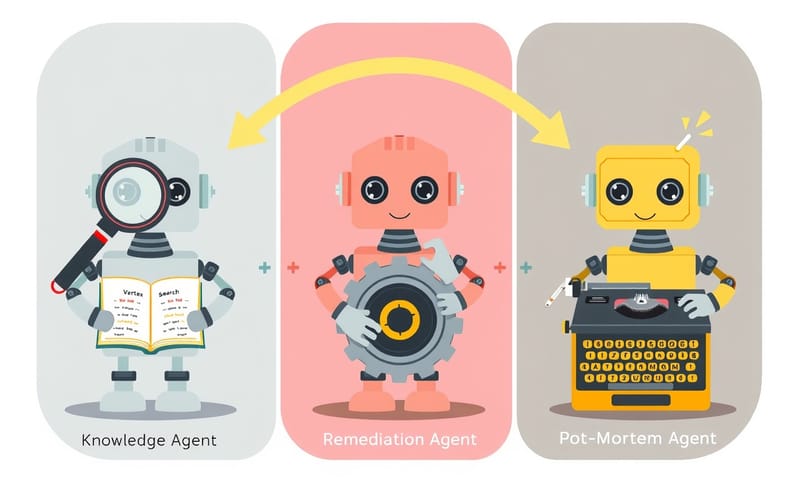
我這次的架構,主要就是用了三個 Agent,它們像接力賽一樣一個傳一個:
- 知識型 Agent (Knowledge Agent):它的任務很單純,就是「找答案」。當收到一個錯誤訊息,它會去翻內部文件(我把它們丟到 Vertex AI Search 裡面索引起來)、查 Google、或是找過去類似事件的紀錄。
- 修復型 Agent (Remediation Agent):如果知識 Agent 找到了明確的解決方案,就換它上場。它才是真的會「動手」的那個,可能會去跑一段 BigQuery 的 SQL、修改 GCS 上的檔案,或是發個通知說「我修好了」。
- 事後報告 Agent (Post-Mortem Agent):等問題解決後,它會負責收尾。把這次事件的 Log、Agent 的所有動作都收集起來,用 Gemini 產生成一份完整的報告,然後再存回 Vertex AI Search。這樣,知識庫就越來越聰明了。
說到這個,不得不提 Google 附的那個 Agent Starter Pack。那個真的...幫了大忙。它給了一個可以直接跑的專案範本,有測試環境、部署腳本,連 Agent 的基本架構都寫好了。不用自己從零開始處理一堆環境設定,可以直接專心在 Agent 的邏輯上。嗯,生產力真的差很多。
三個 Agent 的角色比較
為了讓大家更清楚這三個 Agent 在幹嘛,我弄了個簡單的比較表。你可以把它們想像成一個團隊裡的三個不同角色。
| Agent 角色 | 主要任務 | 使用的工具 | 我的OS... |
|---|---|---|---|
| 知識型 Agent (像團隊裡的資深工程師) |
收到錯誤訊息後,去到處找解決方法。 | Vertex AI Search、Google Search API。 | 就是那個很會 Google 的同事。腦袋裡像有個巨大的知識庫。 |
| 修復型 Agent (像值班的維運人員) |
執行找到的解決方案,真的去改東西。 | BigQuery API、Cloud Storage API、各種 Script。 | 嗯...這個權限要管好。不然它亂改就完蛋了,所以要加很多備份跟確認機制。 |
| 事後報告 Agent (像團隊裡的 Tech Lead 或 PM) |
記錄整個過程,產出報告,讓大家之後能學習。 | Gemini API、Prompt 模板。 | 有點像會議紀錄。把事情整理好,方便歸檔跟以後回顧,我覺得這步超重要。 |
踩到的一些坑和學習
整個過程...嗯...當然不是一路順暢。也遇到一些卡關的地方,順便分享一下。
- 先有具體場景,再想技術:一開始如果想得太抽象,很容易發散。直接鎖定「修復資料管線」這個商業問題,讓整個開發方向變得很明確。
- Gemini Code Assist 很好用:說真的,在調整 Agent 的 instruction (指令) 時,我用了很多 Gemini Code Assist 來幫我潤飾跟驗證 prompt,它給的建議蠻不錯的。
- Vertex AI Search 比想像中複雜:本來以為把文件丟進去就好。後來發現,為了讓 Agent 能穩定地只查內部文件或只查網路,我把它拆成兩個 sub-agent(子代理),一個專門對 Vertex AI Search,一個專門對 Google Search,這樣才比較好控制。
- 單一雲端平台的好處:這次深刻體會到,當你的 Cloud Run、BigQuery、Vertex AI、Secret Manager 全都在 Google Cloud 一個屋簷下時,事情會單純很多。不用處理跨雲的認證、網路延遲這些麻煩事。這點...這點跟我們在台灣很多公司可能習慣的混合雲架構很不一樣。如果你的檔案在 AWS S3,資料庫在自己家機房,那光是串接這些 Agent 的權限和網路設定,複雜度可能就要高上好幾倍了。
對了,還有那個 Agent Starter Pack 裡的 playground,也就是本機測試環境。在把 Agent 部署到雲端之前,先在 playground 裡把邏輯測到順,真的可以省下好幾個小時的 debug 時間。因為在雲上看 Log、重新部署,那個流程慢很多。
下一步呢?還能做什麼?
這次的 Hackathon 專案算是一個起點吧,一個概念驗證。如果真的要把它變成一個成熟的產品,還有很多可以做的。
我自己想到的是...例如,可以加上更多保護機制,像是讓 Agent 在執行高風險操作(比如刪除資料)前,必須先在 Slack 裡面 tag 特定的人,得到批准後才能繼續。這很重要。
或者,可以做得更主動一點。現在是被動等錯誤發生,未來可以整合異常偵測 (Anomaly Detection),在問題還沒擴大、還沒人發現之前,就主動觸發 Agent 去檢查,做到「預防性維護」。
甚至,可以做一個 UI 儀表板,用視覺化的方式看現在有哪些 Agent 正在執行任務、它們的進度到哪、log 是什麼。這樣管理起來會更直覺。
總之,我自己是覺得,這種多代理人工智慧系統(Multi-agent AI systems)的潛力很大,它不只是陪你聊天,而是真的可以成為一個...嗯...自動化的虛擬團隊,去執行複雜的業務流程。如果你對這塊有興趣,真的可以試試看 ADK。
最後想問問大家:如果你的工作流程中,有一件重複性高、又很煩人的事可以交給 AI Agent 處理,你會希望它幫你做什麼? 在下面留言分享看看吧!

