
最近、LLMについてよく考えてる。GPTとかClaudeとか、すごい勢いで新しいのが出てくるよね。正直、どれが一番いいのか、もうよく分からない。
でもね、どんなに賢そうに見えるLLMも、根本的には超高性能な「予測変換」みたいなもの。トレーニングデータにあったパターンを元に、「次に来そうな単語」を予測してるだけ。だから、それっぽい、流暢な文章は作れる。すごく人間らしい文章をね。
ここが落とし穴で。LLMは「正しさ」より「それっぽさ」を優先する。だから、もっともらしい嘘を平気でついちゃう。これが「ハルシネーション」とか言われる現象。なんでこんなことが起きるかって?まあ、理由はいくつかあるけど…
- そもそも学習データにない情報を聞かれた。
- 学習データが古かったり、間違ってたり。
でも、面白いことに、LLMって文脈は理解できる。つまり、プロンプトの中に新しい情報を入れてあげれば、それを元に答えてくれる。この仕組みを使ったのが、今日話す「RAG(Retrieval-Augmented Generation)」、日本語だと「検索拡張生成」かな。
RAGは、ユーザーの質問とLLMの回答の間に立ってくれる橋渡し役みたいな感じ。社内のドキュメントとか、専門的なデータベースみたいな外部の知識源から、関連する情報を引っ張ってきて、それをユーザーの質問と一緒にしてLLMに渡す。そうすると、LLMはその情報を「事実」として扱ってくれるわけ。
これ、特に医療とか法律とか、正確性がめちゃくちゃ大事な分野では、ハルシネーションを劇的に減らせる。LLMが元々持ってる曖昧な知識じゃなくて、検証済みの、ドメインに特化したデータを参照するからね。日本だと、例えばメルカリみたいなテック企業が社内ドキュメントの検索で似たような仕組みを使ってるって話を聞くよね。グローバルな技術だけど、国内でもう普通に使われ始めてる。
要するに、こういうこと。
- LLMだけ → 流暢だけど、嘘をつくかも。
- LLM + RAG → ちゃんとデータに基づいた、信頼できる答えをくれる。
そもそもRAGって何? どうやって動くの?
じゃあ、もうちょっと具体的に見ていこうか。RAGがどういう部品でできてるのか。うん、分解してみるのが一番分かりやすい。
まず、RAGシステムには「知識ベース(Knowledge Base)」が絶対に必要。これは、専門情報とか、社外秘のドキュメントとか、とにかくLLMが知らないであろう情報を保管しておく倉庫みたいなもの。これがなきゃ始まらない。
で、この倉庫があると、システムはこんな風に動く。
- まず、「レトリバー(Retriever)」が知識ベースの中から、質問に関連しそうな情報を探し出す。
- 次に、その見つけてきた情報を、ユーザーの元の質問に「くっつける(Augment)」。まあ、このプロセス自体を「Augmenter」って呼ぶこともあるけど、実際には独立した部品というより、ただ情報を合体させる「処理」だね。
- 最後に、情報が追加された質問を受け取った「LLM(Generator)」が、その情報を元に回答を「生成する(Generate)」。
だから、Retrieval-Augmented Generationっていう名前は、本当にそのまんま。処理の流れをそのまま説明してる。
- Retrieval (検索) - 関連情報を見つける。
- Augmentation (拡張) - 見つけた情報を質問と合体させる。
- Generation (生成) - LLMが最終的な答えを作る。
この流れを図にすると、もっと分かりやすいかな。
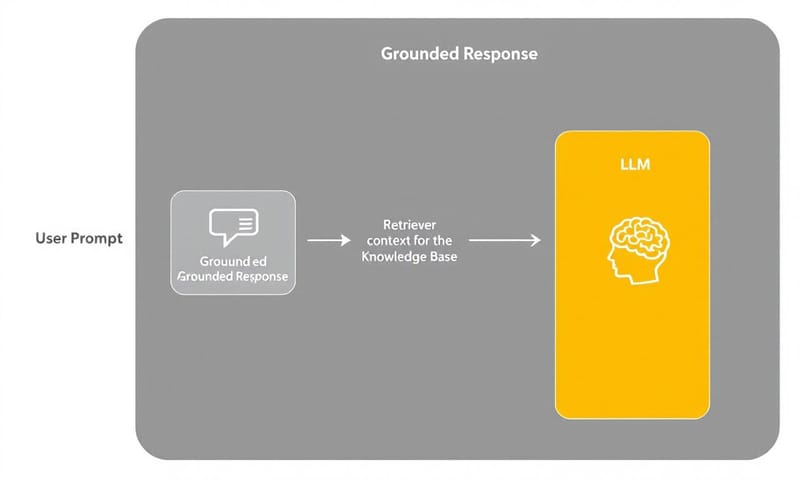
RAGがないと、LLMとのやり取りはシンプルだけど、限界がある。ユーザーの質問 → LLM → それっぽい回答。これだと、LLMが知らないことは、自信満々に間違える。
でもRAGが入ると、こう変わる。ユーザーの質問 → RAG(レトリバー)→ LLM(生成)→ データに基づいた回答。この一手間が、ゲームチェンジャーなんだよね。LLMが暗記に頼るんじゃなくて、その場でカンニングペーパーを見ながら答えられるようになる感じ。うん、そんな感じだ。
RAGの心臓部、「レトリバー」を深掘りする
RAGシステムの性能は、正直、この「レトリバー」の性能でほぼ決まる。だって、どんなに賢いLLMでも、渡される情報が的外れだったら、良い答えなんて作れるわけないから。だから、まずこのレトリバーが何をしてるのか、ちゃんと理解するのが大事。
レトリバーの仕事は、大きく分けて4つの要素で考えられる。目的、手法、スコアリング、評価。まあ、公式な分類じゃないけど、個人的にはこう考えるとスッキリする。
- ゴール(Goals) - そもそも「何を」探したいのか?
- メソッド(Methods) - 「どうやって」効率的に探すのか?
- スコアリング(Scoring Functions) - 見つけた候補を「どうやって」順位付けするのか?
- 評価指標(Evaluation Metrics) - その検索結果は「どれくらい良い」のか?
この順番で見ていこう。
レトリバーの手法(メソッド)
ゴールが決まったら、次は「どうやって探すか」という具体的な手法。これが一番面白いところかもしれない。大きく分けて、キーワード検索、セマンティック検索、メタデータ検索、そしてそれらを組み合わせたハイブリッド検索がある。
手法1:キーワード検索
一番古典的で分かりやすい方法。ユーザーが入力したクエリに含まれる「キーワード」が、ドキュメントに含まれているかを探す。代表的なのがTF-IDFとBM25。
TF-IDF: 古典だけど、まだ現役
TF-IDFは「Term Frequency - Inverse Document Frequency」の略。考え方はシンプルで、2つの指標を掛け合わせる。
- TF (Term Frequency): ある単語が「その」ドキュメント内でどれだけ頻繁に出てくるか。頻繁なら重要かも。
- IDF (Inverse Document Frequency): ある単語が「全体」のドキュメントの中でどれだけ珍しいか。珍しい単語ほど、特定のドキュメントを特徴づける力が強い。
つまり、「そのドキュメントではよく出るけど、他のドキュメントではあまり見かけない単語」に高いスコアがつく。例えば、宇宙に関するドキュメント群で「ロケット」という単語は頻出するからIDFは低いけど、「はやぶさ2」という単語は特定のドキュメントにしか出てこないからIDFが高くなる、みたいな。
BM25: TF-IDFの賢い後継者
BM25は、TF-IDFの進化版みたいなもの。TF-IDFには弱点があって、
- 単語の出現回数が多すぎるとスコアが青天井になる。
- 単純に長いドキュメントが有利になりがち。
BM25は、この2点をうまく調整してくれる。単語の出現回数が増えてもスコアの伸びがだんだん緩やかになる仕組み(飽和)と、ドキュメントの長さを考慮した、より賢い正規化を取り入れている。今だと、キーワード検索といえば、だいたいBM25が使われることが多いかな。
手法2:セマンティック検索
キーワード検索が「単語の一致」を見るのに対して、セマンティック検索、まあ「ベクトル検索」とも呼ばれるけど、これは「意味の近さ」を見る。正直、こっちが最近の主流。
「車」と「自動車」は違う単語だけど、意味は同じ。こういう関係性を捉えられるのがセマンティック検索の強み。どうやってるかというと、「埋め込み(Embeddings)」っていう技術を使ってる。
言葉や文章を、高次元のベクトル(数字の羅列)に変換するんだ。このベクトル空間では、意味が近い単語や文章は、物理的に「近く」に配置される。逆に、意味が遠いものは「遠く」に配置される。

このベクトルを使って、クエリのベクトルと一番「近い」ドキュメントのベクトルを探しにいく。これがセマンティック検索の仕組み。
k-NN: 一番素直だけど、力任せな方法
k-Nearest Neighbors(k近傍法)。これは、クエリのベクトルと、知識ベースにある「全ての」ドキュメントのベクトルとの距離を総当たりで計算して、一番近いk個を見つける方法。正確だけど、ドキュメントが100万件、1億件とかになると、計算量が爆発して現実的じゃない。ブルートフォース、力任せすぎるんだよね。
ANN系 (HNSWなど): 速さを手に入れた賢い方法
そこで出てくるのがApproximate Nearest Neighbor(近似最近傍探索)、略してANN。これは「完全に正確じゃなくてもいいから、そこそこ近いやつを爆速で見つけてよ」という考え方。その代表格がHNSW (Hierarchical Navigable Small World)。
HNSWは、ベクトルをグラフ構造で、しかも階層的に管理する。検索するときは、まず一番上の粗い階層で「だいたいこの辺かな?」って当たりをつけて、だんだん下の細かい階層に降りていって、候補を絞り込んでいく。高速道路で一気に目的地近くのインターチェンジまで行って、そこから一般道で目的地を探す感じ。これにより、巨大なデータセットでもミリ秒単位での検索が可能になる。PineconeとかWeaviateみたいなベクトルデータベースの多くが、裏側でこのHNSWや類似のアルゴリズムを使ってる。
手法3:メタデータ検索
これは一番シンプル。ドキュメントの中身じゃなくて、付随する情報(メタデータ)で絞り込む。例えば、「作成者:田中」「作成日:2023年以降」「カテゴリ:法務」みたいな。SQLのWHERE句みたいなもんだね。速いし確実だけど、本文の内容は一切見ないから、これ単体だとあまり柔軟性はない。
手法4:ハイブリッド検索
で、結局のところ、実運用ではこれが一番多い。ハイブリッド検索。キーワード検索とセマンティック検索、それにメタデータフィルタリングを全部組み合わせる方法。
なんでかっていうと、それぞれに得意不得意があるから。
- キーワード検索: 製品名や専門用語みたいな、固有名詞の完全一致に強い。
- セマンティック検索: 「〇〇する方法」みたいな、曖昧な概念や意図を汲み取るのが得意。
- メタデータ検索: 検索範囲を事前にガバッと絞り込める。
これらを組み合わせることで、それぞれの良いとこ取りができる。例えば、最初にメタデータで期間を絞って、その中でセマンティック検索とキーワード検索を両方実行して、それぞれのスコアを重み付けして合算し、最終的なランキングを作る、みたいなやり方。手間はかかるけど、一番ロバストな結果が得られる。
ちょっと、ここまでをまとめてみようか。
| 検索手法 | 長所(個人的な感想) | 短所(ハマりどころ) | 使いどころ |
|---|---|---|---|
| キーワード検索 (BM25など) |
固有名詞とか、専門用語に強い。期待通りの動きをするから安心感がある。 | 「車」と「自動車」を区別できない。言い換えに弱い。あと、文章が長いとノイズを拾いがち。 | 製品マニュアルとか、エラーコードの検索とか。 |
| セマンティック検索 (HNSWなど) |
すごい。意図を汲み取ってくれる。「お腹が痛いときの食事」で「消化に良い食べ物」の記事を出してくれたり。 | たまに「なんでこれ?」っていう、意味が飛びすぎた結果を返すことがある。あと、埋め込みモデルの選択が超重要。 | 一般的なQ&Aシステムとか、ブログ記事の関連記事検索とか。 |
| メタデータ検索 | 速い。とにかく速い。検索範囲を事前に絞れるから、計算コスト削減に貢献してくれる。 | 柔軟性ゼロ。タグ付けが雑だと、何も見つからなくなる。運用が地味に大変。 | 大規模な文書DBで、「まず部署で絞ってから探す」みたいな使い方。 |
| ハイブリッド検索 | 現状、最強だと思う。キーワードの正確さと、セマンティックの柔軟性を両立できる。 | チューニングが地獄。キーワードとセマンティックのスコアの重みをどうするか、正解がない。職人技の世界。 | 本番環境で使う、ちゃんとしたRAGシステムなら、ほぼこれ。 |
スコアリング関数:何をもって「良い」とするか
レトリバーが候補を見つけてきた後、それをどうやって順位付けするか。それがスコアリング関数の役目。これも、検索手法の中に組み込まれてる機能だけど、意識的に分けて考えると理解しやすい。
- キーワード検索の場合: さっき話したTF-IDFやBM25のスコアそのものが使われる。スコアが高いほど上位。
- セマンティック検索の場合: ベクトル間の「距離」や「角度」を計算する。
- コサイン類似度: ベクトルの向きがどれだけ似ているかを見る。一番よく使われるかな。1に近いほど似ている。
- ユークリッド距離: ベクトル間の直線距離。近いほど似ている。
- ハイブリッド検索の場合: これがまた難しいんだけど、キーワード検索のスコアとセマンティック検索のスコアを正規化して、
最終スコア = α * (セマンティックスコア) + (1-α) * (キーワードスコア)みたいに重み付けして合算することが多い。このαの値をどうするかが腕の見せ所。
評価指標:作ったレトリバーは本当に「良い」のか?
さて、ここまででレトリバーを作る方法は分かった。でも、作ったものが本当にうまく機能しているか、どうやって測ればいいんだろう。「なんかいい感じ」じゃダメなんだよね。ちゃんと数字で評価しないと、改善のしようがない。
ここで出てくるのが、情報検索の分野で昔から使われている評価指標。Precision、Recall、そしてMAP、MRR、nDCGあたりが代表的。

PrecisionとRecall: 基本の「き」
まず、基本となるのがこの2つ。
- Precision (適合率): 「レトリバーが見つけてきたドキュメントのうち、本当に正解だったものの割合」。高ければ、検索結果にノイズが少ないってこと。
- Recall (再現率): 「全ての正解ドキュメントのうち、レトリバーがどれだけ見つけられたかの割合」。高ければ、取りこぼしが少ないってこと。
この2つはトレードオフの関係にある。Precisionを上げようとすると(例えば、すごく自信があるものだけを返すようにすると)、Recallは下がる(取りこぼしが増える)。逆にRecallを上げようとすると(少しでも関係ありそうなものを全部返すと)、Precisionは下がる(ノイズが増える)。このバランスが大事。
Precision@k と Recall@k: もっと実用的な指標
実際には、検索結果を全部見るなんてことはしない。RAGでも、LLMに渡すのは上位k件(例えば3件とか5件)だけ。だから、「上位k件の中でのPrecision/Recall」を測るのが一般的。これがPrecision@k、Recall@k。
ランキングを評価する指標たち (MAP, MRR, nDCG)
もっと重要なのは、「正しいドキュメントがリストのどこにあるか」だ。正解が100位に出てきても意味ないよね。やっぱり1位に出てきてほしい。この「ランキングの順序」を評価するのが、MAP, MRR, nDCGといった指標。
- MRR (Mean Reciprocal Rank): 「最初の正解が、検索結果の何番目に出てきたか」に注目する指標。例えば、最初の正解が3位ならスコアは1/3。すぐに答えが見つかってほしいナビゲーショナルな検索の評価に向いてる。
- MAP (Mean Average Precision): 全ての正解ドキュメントが、どれだけ上位にランクされているかを総合的に評価する。MRRと違って、2つ目以降の正解ドキュメントの順位も考慮される。
- nDCG (normalized Discounted Cumulative Gain): これが一番イケてるかもしれない。まず、単なる「正解/不正解」じゃなくて、「すごく関連してる(2点)」「まあまあ関連してる(1点)」みたいに、関連度にレベルをつけられる。そして、順位が下がるほどスコアにペナルティ(discount)をかける。これを理想的なランキング(IDCG)で正規化(normalize)することで、0から1のスコアを出す。ランキングの質を評価するなら、これが一番信頼性が高いと言われてる。
これらの指標を使って、例えばBM25とセマンティック検索のnDCGを比較して、「今回のタスクではセマンティック検索の方が良いな」とか、ハイブリッド検索の重みαを調整してnDCGが最大になる点を探す、といった改善を進めていくわけ。
まとめというか、今のところの感想
ここまでRAGの心臓部であるレトリバーの内部構造について、つらつらと書いてみた。ゴール、メソッド、スコアリング、そして評価。こうやって分解してみると、RAGってただLLMに何かを食わせるだけの単純な技術じゃないってことが分かると思う。
特に、検索手法の選択と、それをどう評価するかっていう部分は、かなり奥が深い。正直、ここがRAGプロジェクトの成否を分けると言っても過言じゃない。理論は分かっていても、実際に良いレトリバーを作るのは本当に大変なんだよね…。まあ、そこが面白いところでもあるんだけど。
今回は「どうやって動くか」という内部の理論に焦点を当てたけど、次回は、これらの部品をどうやって組み上げて、実用的なシステムにしていくか、という「アプリケーション理論」について話せたらなと思ってる。
ちょっと考えてみてほしいんだけど…
もしあなたが自分の会社のドキュメントを検索するRAGシステムを作るとしたら、どの検索手法を一番重視する?
- A) 専門用語を正確に拾える「キーワード検索」
- B) 曖昧な質問にも答えてくれる「セマンティック検索」
- C) やっぱり両方大事だから「ハイブリッド検索」
理由と一緒に、もしよかったらどこかで教えてください。


