
最近、機械学習のプロジェクトで改めて考えてたんだけど、モデルの精度って、結局どれだけ「データの文脈」を読めるかにかかってるんだよね。単に個々のデータを眺めるだけじゃなくて、その裏にある関係性というか、ストーリーというか。で、その「文脈」の正体が、今日話したい『交互作用』ってやつなんだ。
…うーん、いきなり言われてもピンとこないかな。もっと簡単に言うと、特徴量Aと特徴量Bがあったとして、それぞれの効果を単純に足し合わせるだけじゃ説明できない、何かこう…「合わせ技」みたいな効果が出ること。1+1が2じゃなくて、3にも4にもなる。そういうイメージ。この「化学反応」を見つけられるかどうかが、モデルの性能を一段階、いや二段階上げるための鍵になることが結構あるんだ。
要するに、特徴量同士の「合わせ技」を見つけるのが交互作用ってこと。
そう、本当にこれに尽きる。個々の特徴量がどれだけ優秀でも、それだけじゃ見えてこないパターンがある。交互作用を考慮に入れることで、モデルはもっと複雑で、より現実に近いデータの世界を理解できるようになる。正直、これを知ってるだけで、特徴量エンジニアリングの幅がグッと広がると思う。
「1+1が3になる」ってどういうこと?具体例で考えてみよう
言葉だけだと分かりにくいから、よく使われる不動産の価格予測の例で話してみようか。
例えば、モデルに「部屋の広さ」と「都心からの距離」っていう2つの特徴量を入れるとする。普通に考えたら、「部屋が広いほど価格は高い」「都心に近いほど価格は高い」ってなるよね。これはまあ、それぞれの特徴量が単独で持ってる効果。
でも、ここに交互作用の視点を入れると、もっと面白いことが見えてくる。例えば、「都心に近い」っていう条件と「部屋が広い」っていう条件が組み合わさった時、価格の上昇率が異常に高くなるかもしれない。「都心の広々とした物件」っていうのは、単に「広い」とか「都心」っていう価値を足し算しただけじゃなくて、そこに「希少性」とか「ステータス」みたいな、掛け算的な価値が生まれるから。これが交互作用。
逆に、「郊外」で「部屋がめちゃくちゃ広い」物件は、もしかしたら価格がそこまで上がらないかもしれない。だって、郊外なら広いのが当たり前だったりするしね。つまり、「部屋の広さ」っていう特徴量の効果は、「場所」っていう別の特徴量によって全然変わってくるってこと。これが分かると、モデルはもっと賢い予測ができるようになるわけだ。

あ、ちなみに、こういう話はアメリカの不動産市場の分析とかでもよく出てくるけど、日本の場合はまたちょっと違うかもね。例えば、日本では「駅からの徒歩分数」がめちゃくちゃ重要だったりする。だから、「駅近5分以内」と「築年数5年以内」の組み合わせは、もう足し算じゃなくて掛け算レベルで価格に影響するかもしれない。e-Statみたいな政府の統計データで地域ごとの特性を調べて、仮説を立ててみると面白い発見があるかも。
じゃあ、どうやって交互作用を見つけて、モデルに組み込むの?
OK、じゃあ本題。この「合わせ技」をどうやって見つけるか。方法は大きく分けて2つあるんだ。自分で地道に探す「手動」の方法と、モデルに丸投げしちゃう「自動」の方法。
手動で「これ、怪しいな」って組み合わせを作る
一番シンプルで直感的なのがこれ。さっきの不動産の例みたいに、「この特徴量とこの特徴量、組み合わせたら何か起きそうだな」っていうのを、ドメイン知識とかデータの探索的分析(EDA)から見つけ出して、新しい特徴量として作っちゃう。
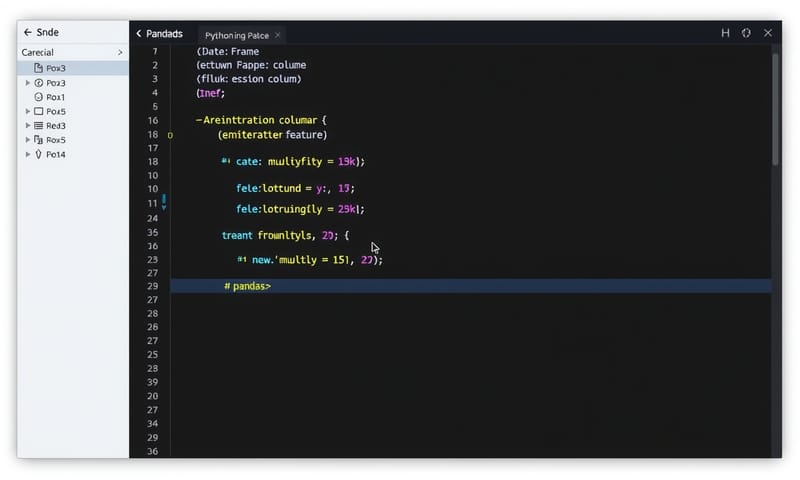
一番簡単なのは、2つの特徴量を掛け算すること。例えば、pandasを使ってるならこんな感じ。
# Python (pandas) で交互作用特徴量を作る例
import pandas as pd
# サンプルデータを作成
df = pd.DataFrame({
'広さ_sqm': [50, 70, 30, 90],
'都心フラグ': [1, 1, 0, 0] # 1が都心、0が郊外
})
# 「広さ」と「都心フラグ」の交互作用(掛け算)を追加
df['広さ_x_都心'] = df['広さ_sqm'] * df['都心フラグ']
print(df)
# 広さ_sqm 都心フラグ 広さ_x_都心
# 0 50 1 50
# 1 70 1 70
# 2 30 0 0
# 3 90 0 0
ほら、こうすると「都心の物件」の時だけ「広さ」がそのまま値として入る新しい特徴量ができた。モデルはこれを使って「都心における広さの効果」を学習しやすくなる。掛け算だけじゃなくて、割り算とか、もっと複雑な組み合わせを試すのもアリ。これはもう、アイデアと試行錯誤の世界だね。
モデルの力に頼る(ツリー系モデルの得意技)
もう一つの方法は、交互作用を見つけるのが得意なモデルを使うこと。代表的なのが、決定木をベースにしたモデル。…そう、ランダムフォレストとか、LightGBMみたいな勾配ブースティング系だね。
なんでこれらが得意かっていうと、決定木ってデータを分割していくプロセスそのものが、交互作用を見つけてるようなもんだから。例えば、まず「都心からの距離が10km以内か?」で分割して、次にその中で「部屋の広さが70平米以上か?」で分割する、みたいな。これって、実質的に「都心に近くて広い物件」っていう条件でデータを分けてるわけだから、自然と交互作用を捉えてるんだよね。
だから、特徴量がめちゃくちゃ多くて、どの組み合わせが効くか見当もつかない…なんて時は、とりあえずLightGBMとかに入れてみちゃうのが手っ取り早い。モデルが勝手に重要な交互作用を見つけて学習してくれるから。
手動でやるべき?それともモデルに任せる?
じゃあ、どっちがいいの?って話になるよね。これはケースバイケース。個人的には、こんな感じで使い分けてるかな。
| アプローチ | どんな時に使う? | メリット | 注意点 |
|---|---|---|---|
| 手動で特徴量を作る | 特徴量の数が少なめ。ドメイン知識があって「この組み合わせは効くはず!」っていう強い仮説がある時。 | ・解釈しやすい(どの組み合わせが効いたか一目瞭然)。 ・線形モデルみたいな単純なモデルでも、表現力が上がる。 |
・手間がかかる。 ・どの組み合わせが当たるか分からない(総当たりは無理)。 ・思い込みで的外れな特徴量を作っちゃうことも。 |
| モデルに任せる (ツリー系) | 特徴量の数が多い。交互作用の当たりがつかない時。とにかく早く精度を出したい時。 | ・自動で複雑な交互作用を見つけてくれる。 ・手間が少ない(scikit-learnとか使えばすぐ)。 |
・どの交互作用が効いてるのか、ちょっと分かりにくい。 ・データが少ないと、変な交互作用を学習して過学習するリスクも。 |
要するに、説明責任がすごく大事なプロジェクトとか、なんでこの予測になったかをとことん説明しなきゃいけない時は、手動で解釈しやすい交互作用項を入れるのがいい。逆に、Kaggleみたいに精度こそ正義!みたいなコンペなら、とりあえず勾配ブースティングに突っ込んでみるのが定石だよね。
交互作用の「罠」:やりすぎ注意!
ここまで聞くと「よーし、じゃあ手当たり次第に特徴量を掛け合わせて突っ込むぞ!」って思うかもしれないけど、ちょっと待って。それ、一番やっちゃいけないやつ。
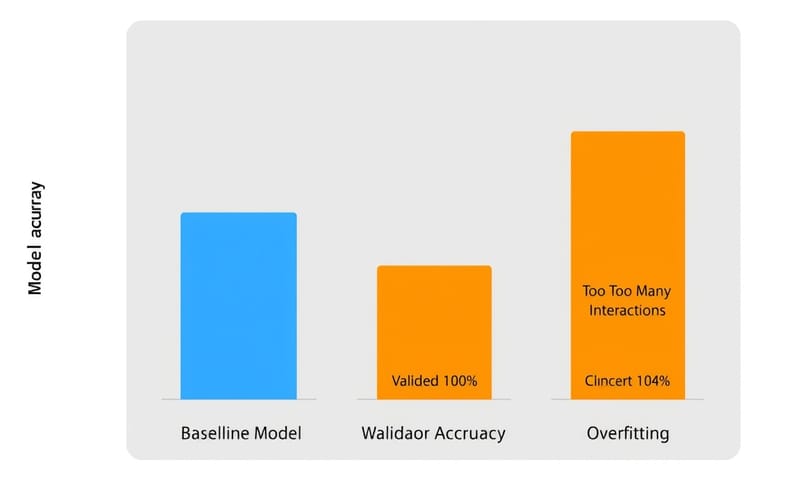
交互作用は強力な武器だけど、同時に「諸刃の剣」でもある。一番の危険は、過学習(Overfitting)を引き起こすこと。
特徴量の組み合わせをむやみに増やすと、モデルは訓練データにだけ存在する「たまたまのパターン」を学習しすぎてしまうんだ。例えば、訓練データの中に「火曜日の雨の日に、30代男性がたまたま特定の商品を3個買った」っていうデータが1件だけあったとする。交互作用をたくさん作ると、モデルが「火曜日×雨×30代男性 ⇒ この商品を買う!」みたいな、極端すぎるルールを学習しちゃう可能性がある。もちろん、そんなルールは未知のデータ(テストデータ)には全く通用しない。結果、訓練データのスコアはいいのに、本番では全然使えないモデルが出来上がってしまう。
これは「次元の呪い」とも関係してる。特徴量の組み合わせは、元の特徴量の数が増えると爆発的に増えるからね。100個の特徴量から2つの組み合わせを考えるだけでも、約5000通り。全部試すなんて現実的じゃないし、モデルを混乱させるだけ。
よくある誤解とか、落とし穴
最後に、交互作用を考えるときによくある勘違いをいくつか。これ、結構大事。
一つ目は、「相関が高い ≠ 交互作用がある」ってこと。2つの特徴量が似たような動きをしてるからといって、組み合わせた時に特別な効果があるとは限らない。むしろ、似すぎてる特徴量なら片方いらない、ってなることの方が多いかも。交互作用は、あくまで「組み合わせた時の追加効果」だからね。
もう一つは、「交互作用を追加すれば、必ず精度が上がるわけじゃない」ってこと。さっきの過学習の話もそうだけど、意味のない交互作用はノイズになるだけ。追加したら、ちゃんと精度が改善したか、特に未知のデータに対する精度(CVスコアとか)が上がったかを冷静に評価する必要がある。闇雲に追加するのは、ただのギャンブルになっちゃう。
個人的には、まずはドメイン知識から2~3個、確度の高そうな交互作用を作って試してみる。それで効果があったら、SHAP (SHapley Additive exPlanations) みたいなモデルの解釈ツールを使って、ツリーモデルが他にどんな交互作用を重要視してるかヒントをもらったりするかな。地道だけど、これが一番確実な気がする。
というわけで、今日は特徴量の交互作用の話をしてみたけど、どうだったかな。この「合わせ技」を使いこなせるようになると、モデル作りが一段と楽しくなるし、何より「データと対話してる感」がすごく増すんだ。ぜひ、次のプロジェクトで試してみてほしい。
あなたの経験を教えて!
あなたのデータで、思わぬ特徴量の組み合わせがモデルの精度を劇的に上げた経験はありますか?例えば、「時間帯」と「商品のカテゴリ」とか、「天気」と「サイトの滞在時間」とか。ぜひコメントで教えてください!


