
最近考えてたんだけど、MLの推論でKafkaを使うって話。リアルタイムで予測を返すシステムね。これ、一番やっちゃいけないミスって、同じリクエストに対して2回答えを返しちゃうこと。もっと最悪なのは、2回違う答えを返すこと。
「Exactly-once」って言葉、よく聞くけど、これ、設定のチェックボックスをオンにすればOKみたいな単純な話じゃないんだよね。正直、考え方そのものを変えないといけない。トピックの設計から、キーの決め方、リトライの処理、モデルのコードが外部とどう連携するかまで、全部に関わってくる。
先說結論
ML推論システムで一貫性を保ちたいなら、Kafkaのトランザクションを使って「Read-Process-Write」のサイクルをアトミックにすること。これに尽きる。もし何か失敗したら、全部ロールバック。これにより、同じ入力イベントからは、常に「1つの永続的で追跡可能な決定」しか生まれないようにする。これが「Exactly-once思考」の核心かな。
なんで推論の時に「1回だけ」がそんなに大事なの?
学習の時とはわけが違う。学習データはバッチ処理だから、リトライなんて日常茶飯事。でも、推論はそうはいかない。例えば、決済リクエストが来て、特徴量ストアを叩いて、不正利用モデルが動く、みたいなシナリオを想像してみて。もしここで出力がダブったら?
- ユーザーに二重課金してしまう
- 確認メールが2通飛ぶ
- 下流の分析データがぐちゃぐちゃになる
考えただけで恐ろしい。だから、Kafkaの冪等性プロデューサー(idempotent producer)とかトランザクション機能が重要になってくる。これらは「事実上1回だけ」を実現するための部品みたいなもの。つまり、「イベントこそが信頼できる唯一の情報源(Source of Truth)」っていう考え方を持つことが大事。同じキーで同じイベントがまた来たら、確実(deterministic)に同じ結果を返すか、あるいは「もう処理済みだから何もしない」のどっちかにしないといけない。
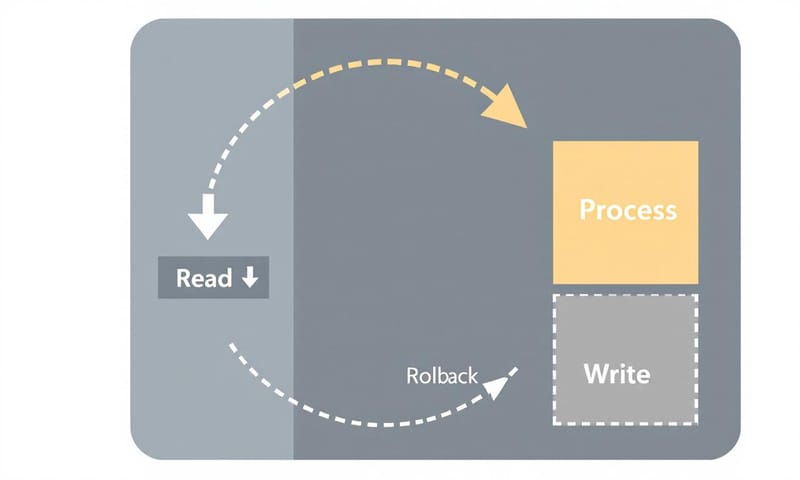
よくある解説だと、冪等性プロデューサーを有効にすればOKみたいに書いてあるけど、正直それだけじゃ足りない。特に、複数のトピックに書き込んだり、外部APIを叩いたりする処理が入ると、途端に話が複雑になるからね。
怎麼做
巨大なフレームワークは必要ない。いくつか、注意深く選んだ制約を設けるだけ。ここからは具体的なステップ。メモみたいな感じだけど。
1. キーとスキーマを安定させる
これは基本中の基本。Kafkaのキーには、order_idとかpayment_idみたいな、ビジネス上の意味を持つキーを使うこと。ランダムなUUIDとかじゃダメ。なぜなら、同じビジネスイベントは同じキーでパーティションに送られるべきだから。これで処理の順序性もある程度担保できる。
あと、スキーマ。お願いだからJSON文字列をそのまま使うのはやめてほしい… AvroとかProtobufみたいな、スキーマバージョニングができる形式を使う。後からイベントを再処理(リプレイ)する時とか、古いバージョンのイベントが遅れて届いた時とかに、どのバージョンのスキーマで処理すべきかが明確になるからね。
2. 冪等なプロデューサーとトランザクション
ここが肝心。プロデューサーの設定で、冪等性(enable.idempotence=true)とトランザクションを有効にする。こうすることで、複数のメッセージ書き込みとオフセットのコミットが、「全部成功」するか「全部失敗」するかのどちらかになる。アトミックになるってこと。
そして、コンシューマー側ではisolation.level=read_committedを設定するのを忘れないように。これをしないと、まだコミットされていない、中途半端に書き込まれたメッセージを読んでしまう可能性がある。大事故のもと。
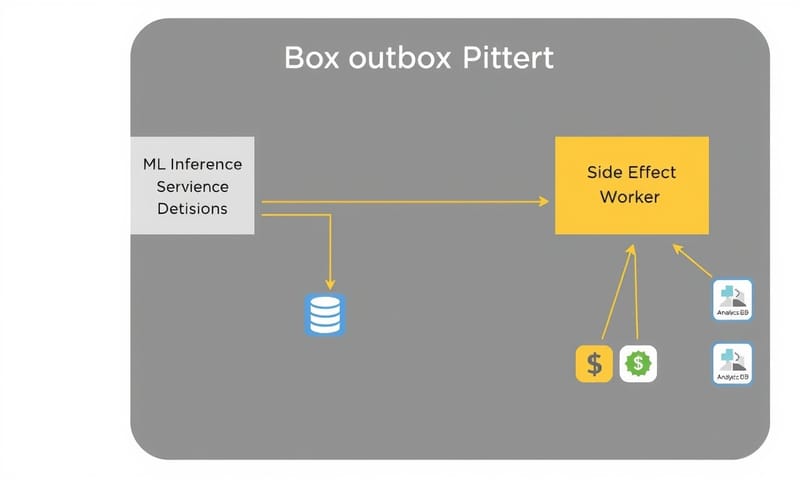
3. 副作用はログ経由で
モデルの推論コードから、直接外部のAPIを叩くのは絶対にダメ。例えば、推論結果に基づいて「メールを送る」とか「決済を確定する」とか。そういう副作用(side effect)を伴う処理は、直接実行するんじゃなくて、まず「アウトボックス・トピック(outbox topic)」っていう別のKafkaトピックに「こういう処理をしてください」というレコードを書き込むだけにする。
で、そのアウトボックス・トピックを監視する別の小さなワーカー(またはKafka Connect)が、実際にAPIを叩く。このワーカーは冪等に作っておく。例えば、リクエストに「デシジョンID(decision_id)」みたいな一意なIDを含めておいて、外部API側が同じIDのりクエストを2回受け取ったら2回目は無視する、みたいな実装。こうすれば、ワーカーがリトライしても、新しい副作用が生まれることはない。
コードで見るとこんな感じ
Javaの例だけど、雰囲気はつかめるはず。リクエストを読んで、結果を書き込んで、オフセットをコミットするまでが1つのトランザクションになってる。
// Gradle: org.apache.kafka:kafka-clients:3.7.0 (example)
// Producer config
Properties prodCfg = new Properties();
prodCfg.put("bootstrap.servers", "kafka:9092");
// ↓ これが冪等性を有効にするおまじない
prodCfg.put("enable.idempotence", "true");
prodCfg.put("acks", "all");
prodCfg.put("max.in.flight.requests.per.connection", "5");
prodCfg.put("retries", Integer.toString(Integer.MAX_VALUE));
// ↓ トランザクションID。ワーカーごとにユニークで固定のものを
prodCfg.put("transactional.id", "inference-tx-1");
KafkaProducer<String, byte[]> producer = new KafkaProducer<>(prodCfg);
producer.initTransactions(); // トランザクションを初期化
// Consumer config
Properties consCfg = new Properties();
consCfg.put("bootstrap.servers", "kafka:9092");
consCfg.put("group.id", "inference-workers");
consCfg.put("enable.auto.commit", "false"); // オフセットは手動でコミット
// ↓ コミット済みのメッセージだけを読む設定
consCfg.put("isolation.level", "read_committed");
KafkaConsumer<String, byte[]> consumer = new KafkaConsumer<>(consCfg);
consumer.subscribe(List.of("inference.requests"));
while (true) {
ConsumerRecords<String, byte[]> batch = consumer.poll(Duration.ofMillis(500));
if (batch.isEmpty()) continue;
// ここからトランザクション開始
producer.beginTransaction();
try {
for (ConsumerRecord<String, byte[]> rec : batch) {
String key = rec.key();
byte[] payload = rec.value();
// runModelは決定論的(同じ入力なら同じ出力)である必要がある
InferenceDecision decision = runModel(payload, "fraud-v42");
ProducerRecord<String, byte[]> out =
new ProducerRecord<>("inference.decisions", key, decision.serialize());
producer.send(out);
}
// オフセットもトランザクションの一部としてコミットする
Map<TopicPartition, OffsetAndMetadata> offsets = new HashMap<>();
for (TopicPartition tp : batch.partitions()) {
List<ConsumerRecord<String, byte[]>> part = batch.records(tp);
long last = part.get(part.size() - 1).offset();
offsets.put(tp, new OffsetAndMetadata(last + 1));
}
producer.sendOffsetsToTransaction(offsets, consCfg.getProperty("group.id"));
// ここで初めて全てがコミットされる
producer.commitTransaction();
} catch (Exception e) {
// 何かあったら全部ロールバック。これで二重出力は防げる。
producer.abortTransaction();
}
}
もしワーカーがproducer.send(out)の後、commitTransaction()の前にクラッシュしたとしても、何も公開されない。再起動後に同じ入力を再処理して、同じ出力を1回だけ生成する。これがミソ。
重複を減らすための他のパターン
トランザクションだけじゃなくて、他にも気をつけることがある。
決定論的なモデルと特徴量
- デプロイごとにモデルのバージョンを固定して、そのバージョン情報を推論結果に含める。
- 特徴量も、ある時点のスナップショットを使うようにする(Point-in-Time Read)。そうしないと、リトライした時に特徴量の値が変わってしまって、違う推論結果が出てしまう可能性がある。
ステートフルな処理にはKafka Streams / Flink
ストリーム上で特徴量の結合(join)とか、ウィンドウ集計みたいなステートフルな処理が必要な場合は、Kafka StreamsとかApache Flinkみたいなフレームワークを使うのが手っ取り早い。これらのフレームワークは、内部に状態ストア(State Store)を持っていて、状態の読み書きと出力トピックへの書き込みを同じトランザクション境界内でやってくれるから、Exactly-onceを維持しやすい。
Confluentの公式ガイドなんかは、この辺りの理想的なアーキテクチャをすごく綺麗に解説してる。でも、前に日本のテックカンファレンスで聞いた話だけど、実際の運用では、特にコンシューマーがリバランスしたり再起動したりした時の「ゾンビインスタンス」問題(古いワーカーがトランザクションを妨害する)の対処が意外と面倒らしい。この辺は、理想論だけじゃなくて、実際の運用ノウハウも大事になってくるね。
結局、どっちがいいの?比較表
じゃあ、今までのやり方(At-least-once)と、今回話したやり方(Exactly-once)を比べるとどうなるか。個人的な意見も入ってるけど。
| 処理セマンティクス | メリット | デメリット / 注意点 | 向いているケース |
|---|---|---|---|
| At-least-once(最低1回) |
実装がシンプル。とにかく速い。 とりあえず動くものを作るならこっち。 |
重複の可能性アリ。二重課金とかマジで怖い。 後から重複排除する処理が必要になることも。面倒くさい。 |
ログ収集とか、最悪データがダブっても許される分析基盤向け。 「落とすよりはマシ」なシナリオ。 |
| Exactly-once(厳密に1回) |
一貫性が保証される。これに尽きる。 監査が楽だし、何より精神的に安心。夜ぐっすり眠れる。 |
少しだけ複雑になる。コードが増える。 レイテンシがほんの少し(数ms〜数十ms)増える。まあ、大抵は許容範囲。 |
決済、不正検知、在庫管理など。 「1回だけ」がビジネス要件として絶対のシステム。 |
リトライとかレイテンシはどうなの?
「結局リトライは発生するんでしょ?」って思うかもしれない。その通り。でも、それでいいんだ。トランザクションを使っていれば、リトライは新しい事実を作るんじゃなくて、同じ事実を再確認するだけの処理になるから。
もちろん、トレードオフはある。Exactly-onceは、トランザクションの調整のために余分な通信(ラウンドトリップ)が発生するから、ほんの少しだけレイテンシは増える。その代わり、監査可能性と、恐怖心なくデータをリプレイできる能力が手に入る。ほとんどのチームにとっては、これは勝ち筋のトレードオフだと思うけどね。
最後のチェックリスト
まとめとして、忘れないための簡単なチェックリスト。
- KafkaキーはビジネスID(
order_idとか)。スキーマはバージョン管理する(Avroとか)。 - プロデューサーは
enable.idempotence=true,acks=allにして、固定のtransactional.idを使う。 - コンシューマーは
isolation.level=read_committedを使って、オフセットはトランザクションの中でコミットする。 - 推論結果には、
model_versionと決定論的なdecision_idを含める。 - メール送信みたいな副作用は、アウトボックス・パターンを使って、冪等なシンクから実行する。
- リプレイしても、同じ出力が生成されるか、あるいは何も生成されないことを確認する。
Exactly-onceは魔法じゃない。規律だ。Kafkaは部品をくれるけど、それを正しく組み立てる—安定したキー、決定論的な処理、ログ化された副作用—のは、結局エンジニアリングの選択なんだよね。まずは小さなサービス1つで試してみて、1日分のデータをリプレイしてみるのがいいと思う。それで出力が変わらなかったら、あなたは正しい道を進んでいる証拠だ。
で、あなたならどうする?
このわずかなレイテンシのオーバーヘッド(数ミリ秒〜数十ミリ秒)と、実装の複雑さ。これを許容してでも「厳密に1回」の保証を取りに行きますか?それとも、ユースケースによっては「最低1回」で十分だと割り切って、シンプルな構成を選びますか?
あなたのチームの状況や担当してるサービスを思い浮かべて、どっちの選択をするか、よかったらコメントで教えてください。


