
最初に言うと、「グループごと相関ヒートマップ」って、見た目は派手だけど地味にややこしい。
ああいう「ごちゃごちゃしたヒートマップ」ね、作ろうと思ったら思ったより罠が多い。
普通にPythonでプロットすればすぐ終わり…って思ったでしょ?いや、データ合わせて、見やすい色にして、グループのラベルまで整えて…ってやると地味に面倒。
データ準備で詰むこと、案外多い
ファイル開けただけで油断しない:「Excelからデータ読めました、はいOK」…じゃ全然終わってない。
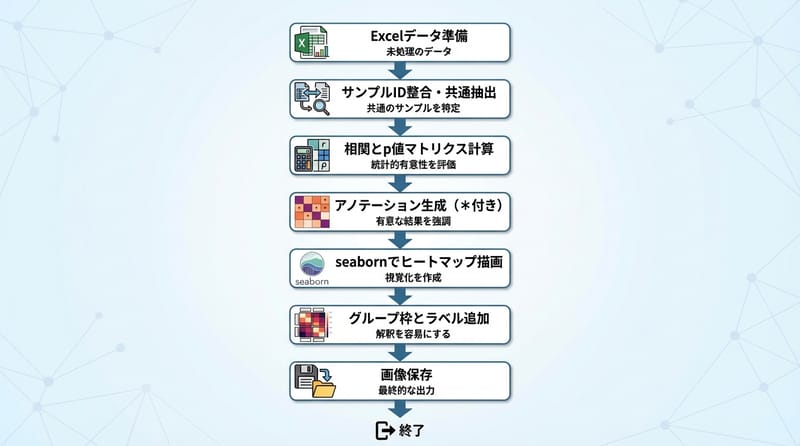
そもそもマイクロブの表と環境要因の表、サンプル(行ラベル)が微妙にズレてるのが普通。「index_col=0」で行名は揃えられても、実際に両方に存在するサンプルだけ抽出しないと、変なズレ起きる。
なんか昔Dcardで見かけたけど、「行がズレて相関めちゃくちゃ」な失敗例、たまにある。
共通サンプルだけ取り出して、順番もピッタリ揃える。それやってから、やっと次に進める。
ラベルリスト化:列名(=特徴名)のリストを「.columns.tolist()」でとるのも地味だけど要る。
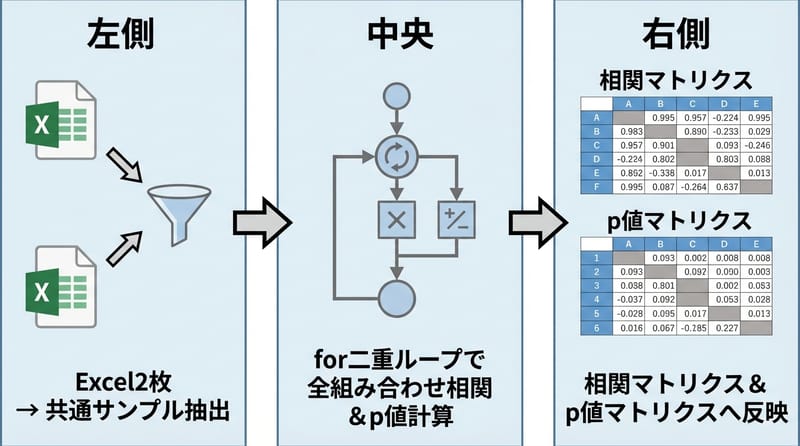
「for二重ループ地獄」でPearson計算。意外と面倒。
ぶっちゃけここが一番手間。
「全部の組み合わせでPearson計算」って、for i in microbe、for j in env、みたいに二重で回すしかない。今どきもっとスマートな方法ないの?…と思ったけど、ぱっと思いつかない。
結果入れる箱:相関係数もp値もDataFrame作って格納。ここはカチっと揃えないと後で絶対後悔する。
型変換の罠:計算後、型がobjectのままだと色々面倒。「astype(float)」で明示的に変える。この操作地味に抜けがち。
アスタリスク注釈(*, **, ***)の賢い付け方、if文やめてnumpy.select使った方がラク
p値で有意水準判定して、星マーク(*とか***)で可視化したい?
昔は「if-elif-else」で頑張ってたけど、np.selectの方がサクッとできる。
ポイント:条件リスト(p<0.001, p<0.01, p<0.05)と対応する記号リスト(***, **, *)、それをnp.selectで一気に配列化。余計なfor文やネスト不要。
「p値条件から注釈を直接量産、np.selectで一発。これ知ってから手動で星つけるの馬鹿らしくなった。」
ヒートマップ描画、seabornのパラメ調整はまあ泥臭い
plt.subplotsででかめの図(12×15)用意して、sns.heatmapで描く。
色設定はcolor_schemesのdictから好きなの選んでね、ぐらい。今時は'viridis'とか'icefire'あたり人気っぽい。なんか最近の論文、変なピンク青の配色多くない?
annotで星を乗せる:アノテーションにさっきの星配列渡す。fmtは''でOK(数値じゃなく文字なので)。
グリッド線の色・幅とか、vmin/vmaxでカラーバー範囲明示するのも地味だけど効く。square=Trueで正方形セル。
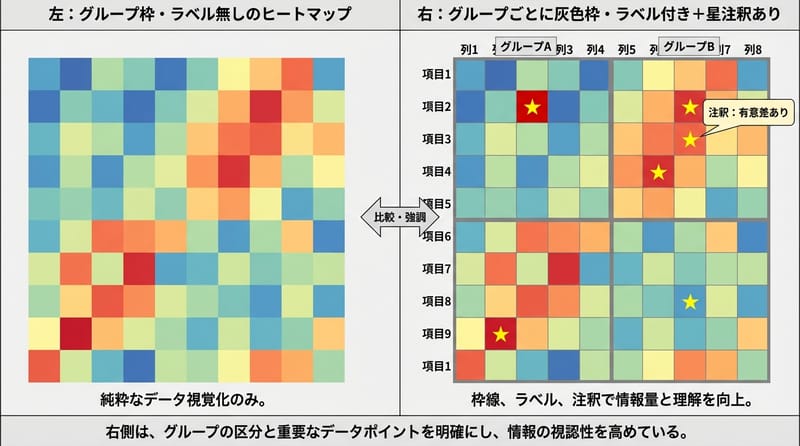
グループラベルを枠で囲む…が結構トリッキー
ここだけは毎回悩む。グループごとの背景を「Rectangle」で塗りつぶして、その上に縦書きラベル。
微妙に軸がズレて見えるの、Matplotlibあるあるだよね。label_x_posみたいな「-0.8」とか謎のマジックナンバーがちょいちょい出てくる。
Y軸の反転:set_ylim(len(microbe_labels), 0)で上を0にする。この小技は「ヒートマップの原点問題」あるある。
グループまたぎの分割線もaxhlineで太めに描く。これがないと見た目一気に雑になる。
「色設定、実はめちゃ大事」— 選ぶ配色で印象が激変する話
ネットで「かっこいいヒートマップ」画像拾うと分かるけど、結局配色しだい。
color_schemesをdictでまとめといて、'viridis'とか'icefire'みたいな定番も、sns.diverging_paletteで独自配色もサクッと切り替え。なんか論文書く時、変なパレット使うと査読で指摘食らうこともあるとか(友人談)。
日本語環境でフォント問題:matplotlibのフォント設定、英語だと'Times New Roman'安定だけど、日本語使うならYu GothicやIPAexあたりに変えると文字化け回避できる。
あと、日本語入るならmathtext.fontsetも見直しといたほうがいい。これ台湾の友だちも困ってたらしい。

気を付けたいこと:サンプルの順番合わせを絶対ミスるな
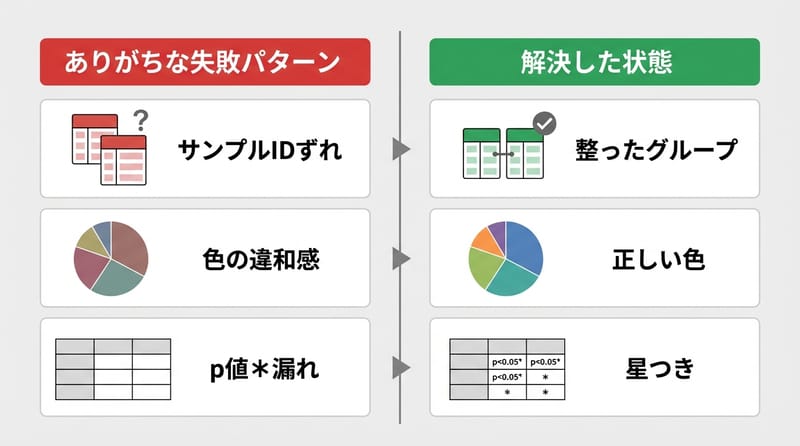
一番やりがちな失敗:microbeとenv、それぞれ「共通サンプルだけ抽出」まではやったのに、順番がズレたままcorrelation計算。これ、気付かずそのまま論文やプレゼン出したら…考えるだけで恐ろしい。
なのでintersection+.loc[common_samples]で、両方のデータをガッチリ合わせる癖をつけたい。
「相関ヒートマップで意味不明なパターン出たら、まずサンプル順番を疑う。ほんとコレ。」
実は「分析前」のデータ整理で勝負が決まってる説
ヒートマップ自体の見た目にばっか目が行くけど、実際一番差がつくのは「データの前処理」。
Excelで「サンプルIDに変な全角スペース混じってる」とか、シート名が微妙に違うとか、台湾でもよく聞く失敗パターン。
公式ツールやチェック方法:本気で数が多い時は、pandasだけじゃなくて「OpenPyXL」使ってExcelを直接読むのもアリ。ヒートマップがズレる原因、大体ファイルのどこかに。
自分がハマった小さな罠と、抜けた瞬間の話
ここだけ完全に雑談モードなんだけど、「matplotlib.use('TkAgg')」って設定、環境によっては全然必要なかったり、逆にないとエラー出ることもあった。
あと、画像保存時にdpi=300で「思ってたよりでかい画像」になってPC固まったことある。保存範囲(bbox)も要調整。
あ、台湾で配布されたサンプルファイル使ったことがあって、その時だけなぜか列名が英語・日本語混じりで地味に面倒だった。日本市場でもラボごとに命名ルール全然違うから、ラベルの正規化は地味だけど絶対やった方が良い。
比較表:「手順ごとに感じる面倒さ・楽さ」
| 工程 | 手間感・コメント |
| Excel読込 | まあ普通。けどシート名違いとか日本語絡むと微妙に詰まる |
| サンプル整合 | 本当にここミスると全て台無し。油断したら負け |
| 相関・p値計算 | for二重ループは地味にダルいけど慣れたらパターン化できる |
| 注釈(*)生成 | np.select知ってれば楽勝。if文で頑張る時代は終わった |
| 描画パラメ調整 | 細かい指定多い。公式ドキュメント読んでも迷うこと多し |
| グループラベル付け | matplotlibの座標指定、未だによく分からん笑。何回も試すしかない |
正直、この方法がベストとは言わないけど
正攻法だけど地味な所に罠が多い。
本気で拡張したいなら、カスタムの可視化クラス作るか、Rでggplot2ヒートマップ試すのもあり。でもPython + seaborn + pandasなら、日本のラボでも台湾の研究会でも普通に通用する。「こだわりたいポイントだけ調整する」ぐらいが、一番コスパ良い。
微アドバイス:いきなり全自動を目指さず、まず手作業で一個ずつ確認しながら作ったほうが「なんかおかしい」にすぐ気づける。
さて、みんなはどこで一番詰まった?
今までヒートマップ系で「ありえないバグ」に遭遇したこと、1回はあるんじゃない?もしかして「p値が全部0.000になった」現象とか、配色ミスって何が何だか分からなくなったとか…。その時どうやって抜けたのか、思い出せる人いたら、ぜひシェアしてほしい。


